الگوریتم خوشه بندی isodata ایزودیتا (آیسودیتا)
سرفصل مطالب
الگوریتم خوشه بندی isodata ایزودیتا (آیسودیتا)
الگوریتم خوشه بندی بدون نظارت isodata ایزودیتا (آیسودیتا) یک روش خوشه بندی سلسله مراتبی است که با استفاده از تراکم دادهها، گروههای مختلف را تشکیل میدهد. این روش بر اساس فاصله بین نقاط داده و نقاط تراکم آنها، گروهبندی میکند. این روش در زمینههایی مانند تجزیه و تحلیل تصویر، شبکهسازی و شناسایی الگو استفاده میشود.
الگوریتم خوشه بندی isodata ایزودیتا (آیسودیتا) تکنیکی برای مقابله با مسائلی که در آن داده ها ذاتاً در ابعاد متعددی توصیف می شوند که در آن هر بعد مربوط به متغیری از مسئله است. چنین مشکلاتی بسیار رایج هستند و بسیاری از آنها که معمولاً با تعداد کمی (3 تا 10) ابعاد توصیف میشوند، در واقع ابعاد بسیار بزرگتری دارند، اما به منظور امکان دستکاری (و توصیف) دادهها ساده شدهاند. . چنین فروپاشی مشکل اغلب مفید و مناسب است، که نشان دهنده اهمیت غالب برخی از پارامترها است. با این حال، یک دسته از مشکلات وجود دارد که برای آنها چنین فروپاشی روابط متقابل قابل توجهی بین پارامترهایی که به داده ها معنی می دهد را از بین می برد.
حوزه تحقیق با عنوان “تشخیص یا شناسایی الگو” در درجه اول شامل تلاش هایی برای توسعه تکنیک هایی است که قادر به مقابله با مشکلات ذاتاً با ابعاد بالا هستند.
تجزیه و تحلیل داده ها از جمله موارد زیر را شامل می شود: «روش هایی برای تجزیه و تحلیل داده ها، تکنیک های تفسیر نتایج چنین رویه هایی، روش های برنامه ریزی برای جمع آوری داده ها به منظور آسان تر، دقیق تر و دقیق تر کردن تجزیه و تحلیل آن، و تمام ماشین آلات و نتایج ( ریاضی) آماری که برای تجزیه و تحلیل داده ها اعمال می شود.
ISODATA، همانطور که از نام آن پیداست، مجموعهای از مراحل تکراری است که تلاش میکند تمام جزئیات ظریف قابل استخراج از دادهها را خلاصه کند. بلکه بر گرایش های مرکزی و ساختار اصلی داده ها تمرکز دارد. همانطور که ISODATA به طور معمول استفاده می شود، سازش بین تلاش برای ذخیره و تجزیه و تحلیل تمام جزئیات و جنبه های داده ها از همان ابتدا (در صورت تمایل، این امر می تواند بعداً در تجزیه و تحلیل بخش های محدودی از داده ها انجام شود) و رویکردی است که تقریباً همه چیز را با هم میانگین می کند. (در واقع، اگر بنا به دلایلی مطلوب بود، هر یک از این دو افراطی با انتخاب مناسب پارامترهای فرآیند خاصی که ISODATA را کنترل می کنند، قابل دستیابی است.)
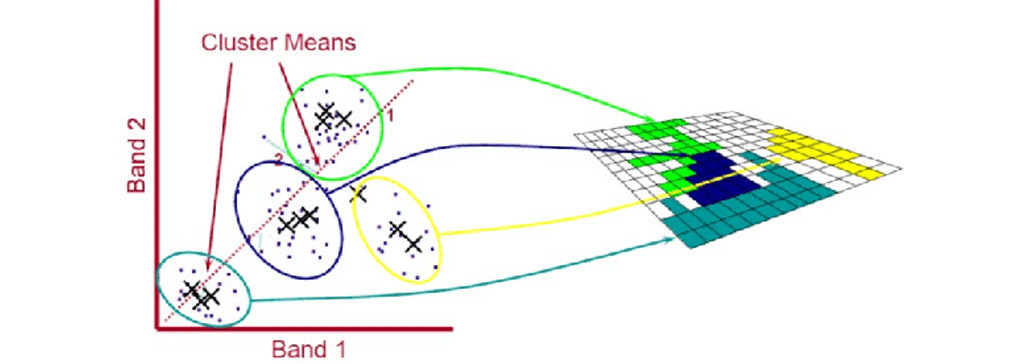
مقایسه همه الگوها با همه الگوهای دیگر برای تعداد زیادی الگو عملی نیست. در عوض، این روش الگوها را با مجموعهای از خوشههای ساخته شده از زیر مجموعههای خود الگوها مقایسه میکند و الگوها را بر اساس این مقایسهها با هم گروهبندی میکند. مقایسه ها با تعیین اندازه گیری فاصله در فضای اندازه گیری انجام می شود. اگر الگوها به «توضیحات یک خوشه» نزدیکتر باشند، با هم گروهبندی میشوند. تعداد خوشه های استفاده شده توسط این تکنیک به گونه ای متفاوت است که به ساختار الگوها در فضای اندازه گیری و پارامترهای فرآیند ISODATA که محقق کنترل می کند بستگی دارد.
هنگامی که بر روی داده هایی استفاده می شود که اطلاعات طبقه بندی برای آنها در دسترس نیست، ISODATA تقریب خوبی با ساختار طبیعی داده ها پیدا می کند، به جای تلاش برای تحمیل ساختار فرضی بر داده ها. با خوشهبندی تنها یک کلاس از الگوها در یک زمان، اطلاعات طبقهبندی میتواند همراه با ISODATA برای ساختار دادهها برای یک مشکل طبقهبندی الگوی خاص استفاده شود. توزیع احتمال داده ها نیازی به دانستن یا حتی فرض وجود ندارد. توسعه یک روش محاسباتی ساده که می تواند برای الگوهای بیش از 100 بعد (به عنوان مثال، الگوهای نوری و شکل موج های پیچیده) اجرا شود، عامل مهمی بود که توسعه این تکنیک را هدایت کرد. ما ISODATA را ابداع کردهایم تا روشهای تجزیه و تحلیل دادههای خودسازماندهی تکراری A را نشان دهیم. (“A” اضافه شد تا ISODATA قابل تلفظ باشد.)
الگوریتم خوشه بندی isodata در یک نگاه :
• ISODATA یک روش خوشه بندی بدون نظارت است.
• نیازی به دانستن تعداد خوشه ها نیست
• الگوریتم خوشه ها را تقسیم و ادغام می کند
• کاربر مقادیر آستانه را برای پارامترها تعریف می کند
• كامپيوتر الگوريتم را از طريق تكرارهای زياد تا رسيدن به آستانه اجرا می كند
تفاوت الگوریتم isodata و k-means
الگوریتم ISODATA شبیه به الگوریتم k-means است با این تفاوت که الگوریتم ISODATA تعداد خوشه های مختلف را مجاز می کند در حالی که k-means فرض می کند که تعداد خوشه ها از قبل مشخص است. هدف از الگوریتم k-means به حداقل رساندن تنوع درون خوشه ای است.
• ایزودیتا یک روش خوشه بندی سلسله مراتبی است که بر اساس فاصله بین نقاط و یا خوشه ها، ساختار درختی از داده ها را ایجاد میکند این روش میتواند به دو شکل تجمیعی (از پایین به بالا) و تقسیمی (از بالا به پایین) انجام شود در روش تجمیعی، هر نقطه در ابتدا یک خوشه است و در هر مرحله، دو خوشه ای که به هم نزدیکتر هستند با هم ترکیب میشوند تا در نهایت یک خوشه ی کلی به دست آید. در روش تقسیمی، همه ی نقاط در ابتدا یک خوشه هستند و در هر مرحله، یک خوشه به دو زیرخوشه تقسیم میشود تا در نهایت هر نقطه یک خوشه باشد این روش مزیت این را دارد که نیازی به تعیین تعداد خوشه ها در ابتدا ندارد و میتواند ساختار سلسله مراتبی داده ها را نشان دهد.
• kmeans یک روش خوشه بندی پارتیشن بندی است که بر اساس کمینه کردن مجموع فاصله های نقاط از مرکز خوشه ها، داده ها را به تعداد مشخصی از خوشه ها تقسیم میکند. این روش به صورت تکراری عمل میکند و در هر مرحله، دو عملیات انجام میدهد: اول، هر نقطه را به خوشه ای که به آن نزدیکتر است اختصاص میدهد و دوم، مرکز هر خوشه را برابر با میانگین نقاط آن خوشه محاسبه میکند. این روش ادامه مییابد تا جایی که تغییری در اختصاص نقاط به خوشه ها رخ ندهد یا تعداد مشخصی از تکرار انجام شود. این روش مزیت این را دارد که ساده و سریع است و میتواند خوشه هایی با شکل کروی را به خوبی تشخیص دهد.
چرا isodata یک روش سلسه مراتبی است و پارتیشن بندی نمی باشد؟
الگوریتم ISODATA یک روش خوشه بندی است که بر اساس تراکم داده ها کار می کند. این الگوریتم به طور خودکار تعداد خوشه ها را تعیین می کند و می تواند خوشه ها را ادغام یا تقسیم کند، که این ویژگی ها آن را از روش های پارتیشن بندی متمایز می کند. روش های پارتیشن بندی، مانند K-means، از ابتدا تعداد خوشه ها را مشخص می کنند و سپس داده ها را بر اساس این تعداد خوشه بندی می کنند. در این روش ها، تعداد خوشه ها ثابت است و تغییر نمی کند. بنابراین، با توجه به این تفاوت ها، ISODATA به عنوان یک روش خوشه بندی سلسله مراتبی در نظر گرفته می شود، نه یک روش پارتیشن بندی.
نحوه عملکرد ISODATA:
- مراکز خوشه ای به طور تصادفی قرار می گیرند و پیکسل ها بر اساس روش کوتاه ترین فاصله تا مرکز تخصیص داده می شوند.
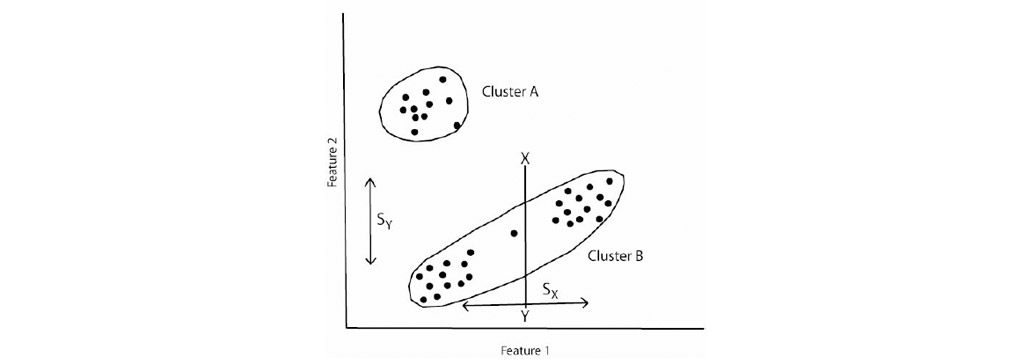
- انحراف معیار در هر خوشه و فاصله بین مراکز خوشه محاسبه می شود.
- اگر یک یا چند انحراف معیار بیشتر از آستانه تعریف شده توسط کاربر باشد، خوشه ها تقسیم می شوند.
- اگر فاصله بین آنها کمتر از آستانه تعریف شده توسط کاربر باشد، خوشه ها ادغام می شوند.
3. تکرار دوم با مراکز خوشه جدید انجام می شود
4. تکرارهای بیشتر تا زمانی که:
i) میانگین فاصله بین مرکز کمتر از آستانه تعریف شده توسط کاربر است،
ii) میانگین تغییر در فاصله بین مرکز بین تکرارها کمتر از یک آستانه باشد، یا
iii) به حداکثر تعداد تکرار رسیده است.
در طول مسیر…
خوشه های مرتبط با تعداد پیکسل های کمتر از حداقل تعیین شده توسط کاربر حذف می شوند.
پیکسلهای تنها یا برای طبقهبندی مجدد در استخر قرار میگیرند یا به عنوان «غیرقابل طبقهبندی» نادیده گرفته میشوند.
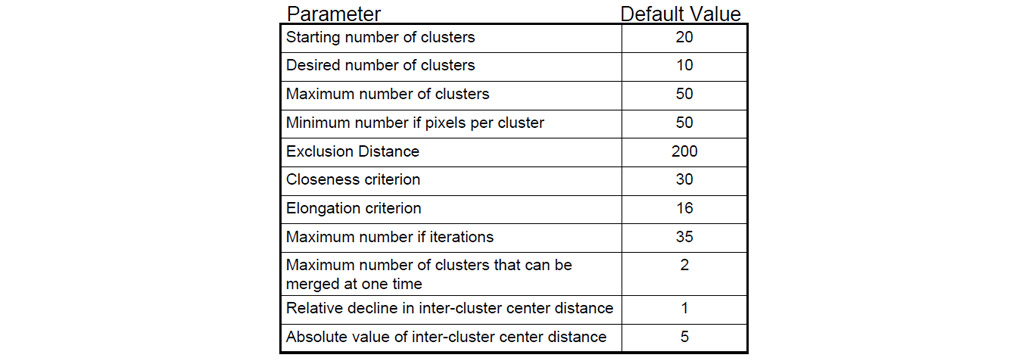
هنگام انتخاب پارامترها:
- آزمایش کنید!
- پیکربندی نهایی تا حد زیادی به پیکربندی شروع بستگی دارد.
- می تواند مختصات مرکز شروع را برای به حداقل رساندن تغییرات ذخیره کند.

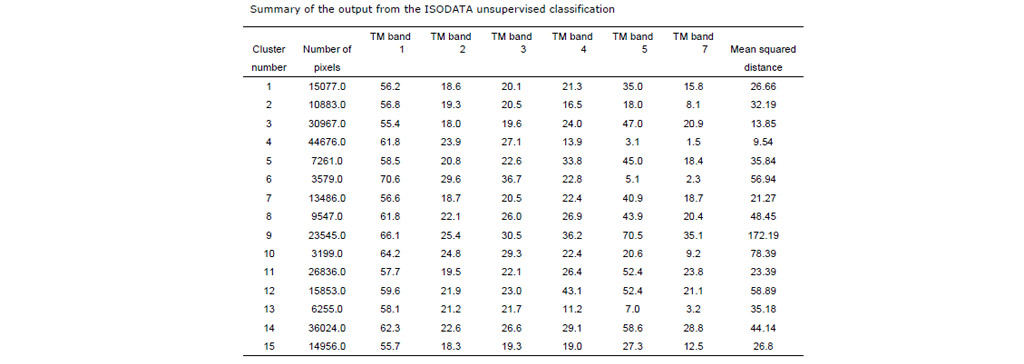
معایب ISODATA
- اگر دادهها بسیار بیساختار باشند، ممکن است زمانبر باشد.
- الگوریتم می تواند از کنترل خارج شود و تنها یک کلاس باقی بماند.
مزایای ISODATA
- لازم نیست از قبل اطلاعات زیادی در مورد داده ها بدانید.
- تلاش کاربر کمی مورد نیاز است.
- ISODATA در شناسایی خوشه های طیفی در داده ها بسیار موثر است.



دیدگاه (3)
سلام . وقت شما بخیر. تشکر می کنم بابت مطالب اموزشی که در اختیار خوانندگان خودتون قرار می دید و برای مطالعه بیشتر از این مطالب استفاده کردم. باتشکر فراوان
سلام خانم سلطانی. وقت شما هم بخیر. خیلی ممنون از کامنت انرژی بخشتون.
از شما سپاسگزارم که به سوالات من جواب میدید و راهنمایی می کنید. و اهمیت میدید به خواست خوانندگان مطالب اموزشی تون . واقعا ممنونم خیلی بمن کمک شد . واقعا ممنونم .