خوشه بندی Clustering
سرفصل مطالب
مقدمه ای بر خوشه بندی Clustering :
خوشه بندی در داده کاوی در اصل نوعی روش یادگیری بدون نظارت است. یک روش یادگیری بدون نظارت روشی است که در آن ما از مجموعه داده های متشکل از داده های ورودی بدون برچسب به عنوان فرآیندی برای یافتن ساختار معنی دار، ویژگی های تولیدی و گروه بندی های ذاتی مجموعه ای از مثال ها استفاده میشود. خوشه بندی وظیفه تقسیم جمعیت یا نقاط داده به تعدادی گروه است به گونه ای که نقاط داده تخصیص داده شده به یک گروه بیشتر به سایر نقاط داده در همان گروه شباهت دارند و با نقاط داده در گروه های دیگر متفاوت است.
در اصل گروه بندی از اشیا بر اساس شباهت و عدم تشابه بین آنها است. خوشه بندی یکی از سخت ترین تکنیک های مدلسازی است. این نه تنها دانش فنی مناسب، بلکه درک خوبی از انواع داده را نیز میطلبد. از آنجا که این تکنیک ذاتاً بسیار ذهنی است، درست ساختن اصول اولیه بسیار حیاتی است. در این مقاله قصد داریم اصول خوشه بندی را بیان کنیم. برای مثال نقاط داده ای در نمودار زیر که به صورت خوشه ای جمع شده اند را میتوان در یک گروه واحد طبقه بندی کرد.

خوشه بندی
خوشه بندی وظیفه تقسیم جمعیت یا نقاط داده به تعدادی گروه است به گونه ای كه نقاط داده در همان گروه ها بیشتر از نقاط دیگر گروه ها به سایر نقاط داده همان گروه شباهت دارد. به عبارت ساده، هدف این است که گروه هایی را با صفات مشابه تفکیک کرده و آنها را به صورت خوشه ای تقسیم کنید.
مثال خوشه بندی
بیایید این را با یک مثال خوشه بندی بررسی کنیم. فرض کنید، شما رئیس یک فروشگاه هستید و میخواهید اولویت های مشتری های خود را برای گسترش کار خود درک کنید. آیا ممکن است شما به جزئیات هر مشتری نگاهی بیندازید و برای هر یک از آنها یک استراتژی تجاری منحصر به فرد طراحی کنید؟ قطعا نه. اما آنچه شما میتوانید انجام دهید اینست که همه مشتری های خود را بر اساس عادت خریدشان در 10 گروه قرار دهید و از یک استراتژی جداگانه برای مشتریان در هر یک از این 10 گروه استفاده کنید. و این همان چیزی است که آن را خوشه بندی مینامیم.

خوشه بندی مشتریان یک استراتژی برای افزایش فروش و افزایش رضایت مشتری
بنابراین، به عبارت ساده، خوشه بندی یادگیری ماشینی فرآیندی است که طی آن گروه هایی را در داده ها ایجاد میکنیم، مانند مشتریان، محصولات، کارمندان، اسناد متنی، به گونه ای که اشیایی که در یک گروه قرار میگیرند بسیاری از خصوصیات مشابه یکدیگر و متفاوت از اشیایی است که در گروه های دیگری که در طی فرآیند ایجاد شده اند قرار میگیرد. Object های مشابه به هم در یک گروه قرار می گیرد.
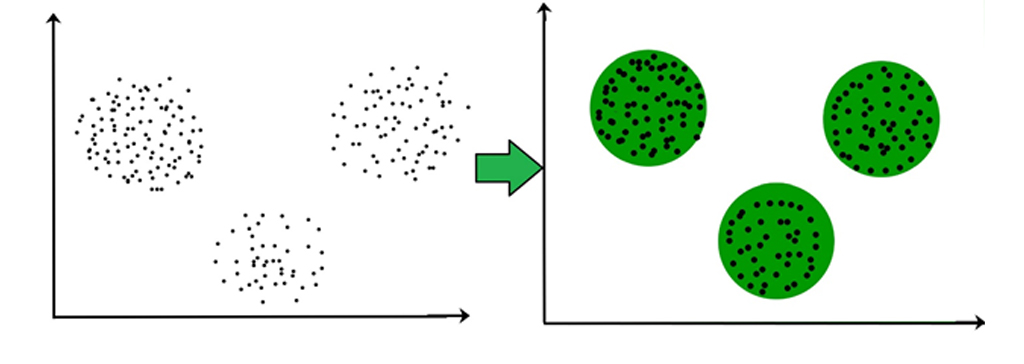
الگوریتم های خوشه بندی داده ها را میگیرند و با استفاده از نوعی معیار تشابه، این گروه ها را تشکیل میدهند؛ بعداً این گروه ها میتوانند در فرایندهای مختلف تجاری مانند بازیابی اطلاعات، تشخیص الگو، پردازش تصویر، فشرده سازی داده ها، بیوانفورماتیک و غیره مورد استفاده قرار گیرند. در فرایند یادگیری ماشین برای خوشه بندی، همانطور که در بالا ذکر شد، یک معیار شباهت مبتنی بر فاصله، نقشی محوری در تصمیم گیری خوشه بندی دارد.
در انواع روش های خوشه بندی برای یک خوشه بندی با کمترین خطا ، باید به دو هدف اصلی دست یابیم: یکی، شباهت بین یک نقطه داده با نقطه دیگر و دوم، تمایز آن نقاط داده مشابه با سایر نقاط است. اساس چنین تقسیماتی با توانایی ما در مقیاس گذاری مجموعه های داده بزرگ آغاز میشود و این یک نقطه شروع اصلی برای ما است.
وقتی این مشکل را پشت سر گذاشتیم، با چالشی روبرو میشویم که داده های ما حاوی انواع مختلفی از ویژگی ها است. داده های طبقه ای، پیوسته و غیره، و ما باید بتوانیم با آن ها کنار بیاییم. اکنون، ما میدانیم که داده های این روزهای ما از نظر ابعاد محدود نیستند، ما داده هایی داریم که ماهیتی چند بعدی دارند. الگوریتم خوشه بندی که قصد استفاده از آن را داریم نیز باید با موفقیت از این مانع عبور کند.
خوشه های مورد نیاز ما نه تنها باید بتوانند نقاط داده را از هم تشخیص دهند بلکه باید فراگیر نیز باشند. مطمئناً، یک معیار فاصله بسیار کمک میکند اما شکل خوشه اغلب به شکل هندسی محدود میشود و بسیاری از نقاط مهم داده از مطالعه حذف میشوند. این مشکل نیز باید مورد توجه قرار گیرد. نتایج حاصل از الگوریتم خوشه بندی باید قابل درک باشد و متناسب با معیارهای کسب و کار باشد و به درستی به حل مشکل تجاری بپردازد. برای پرداختن به نکات مسئله در بالا، مقیاس پذیری، ویژگیها، ابعاد، شکل مرز، نویزها و تفسیر مواردی است که برای حل این مسائل، انواع مختلفی از روش های خوشه بندی را داریم که یک یا بسیاری از این مشکلات را حل میکند.
انواع مختلف خوشه بندی عبارتند از:
خوشه بندی مبتنی بر اتصال (خوشه بندی سلسله مراتبی، Hierarchical clustering)
خوشه بندی مبتنی بر مرکز (روش های پارتیشنبندی، Partitioning methods)
خوشه بندی مبتنی بر توزیع (Distribution-based Clustering)
خوشه بندی مبتنی بر تراکم (روش های مبتنی بر مدل، Model-based methods)
خوشه بندی فازی(Fuzzy Clustering)
خوشه بندی مبتنی بر محدودیت (خوشه نظارت شده، Supervised Clustering)
خوشه بندی سلسله مراتبی
خوشه بندی سلسله مراتبی روشی برای خوشه بندی یادگیری ماشین بدون نظارت است که در آنجا با یک سلسله مراتب تقسیم بندی، برای ساخت خوشه ها شروع میشود. سپس اقدام به تجزیه اشیا (data، داده)بر اساس این سلسله مراتب میکند، از این رو خوشه ها ایجاد میشوند. این روش بر اساس جهت پیشرفت از دو روش پیروی میکند، یعنی جریان از بالا به پایین یا از پایین به بالا برای ایجاد خوشه ها در نظر گرفته شود. اینها به ترتیب تقسیم بندی و رویکرد تجمعی هستند.
رویکرد بالا به پایین (Divisive Approach)
این رویکرد خوشه بندی سلسله مراتبی از یک رویکرد از بالا به پایین پیروی میکند، جایی که ما در نظر میگیریم که تمام نقاط داده متعلق به یک خوشه بزرگ است و سعی میکنیم دادهها را بر اساس منطق خاتمه بخش یا به گروههای کوچکتر تقسیم کنیم. از نقاط داده این منطق خاتمه میتواند بر اساس حداقل مربعات خطای درون یک خوشه باشد یا برای داده های دسته بندی شده، معیار میتواند ضریب جینی درون یک خوشه باشد. از این رو، به طور تکراری، داده هایی را که زمانی به عنوان یک خوشه بزرگ گروه بندی شده بودند، به تعداد N خوشه ی کوچکتر تقسیم میکنیم که اکنون نقاط داده به آن تعلق دارند. باید در نظر گرفته شود که این الگوریتم هنگام تقسیم خوشه ها بسیار “سخت” است. به این معنی که یک خوشه بندی در داخل یک حلقه انجام شود.
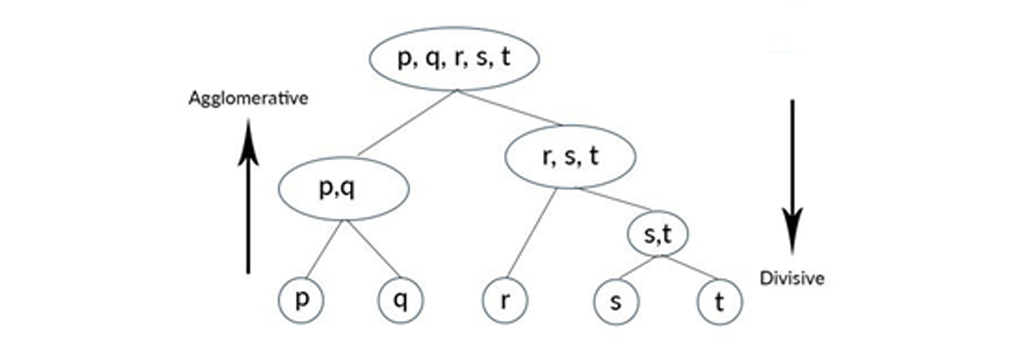
رویکرد پایین به بالا (Agglomerative Approach)
روش پایین به بالا کاملاً بر خلاف بالا به پایین است، جایی که تمام نقاط داده N به عنوان یک عضو واحد از خوشه های N در نظر گرفته میشوند که داده ها در آن تشکیل شده است. ما این خوشه های متعدد N را به صورت تکراری با تعداد کمتری از خوشه ها ترکیب میکنیم، بگذارید بگوییم خوشه های k از این رو نقاط داده را به ترتیب به هر یک از این خوشه ها اختصاص میدهیم. این رویکرد از پایین به بالا است و همچنین در ترکیب خوشه ها از منطق خاتمه استفاده میکند. این منطق میتواند یک معیار مبتنی بر عدد باشد (دیگر خوشه ای بیش از این نقطه وجود ندارد) یا یک معیار فاصله (خوشه ها نباید از هم فاصله داشته باشند تا بتواند ادغام شود) یا معیار واریانس ( افزایش واریانس خوشه در حال ادغام نباید بیش از یک آستانه باشد).
خوشه بندی مبتنی بر Centroid
خوشه بندی مبتنی بر Centroid به عنوان یکی از ساده ترین الگوریتم های خوشه بندی در نظر گرفته میشود، در عین حال موثرترین روش ایجاد خوشه ها و اختصاص نقاط داده به آن است. منطق پشت خوشه بندی مبتنی بر مرکز این است که یک خوشه مشخص شده و توسط یک بردار مرکزی نشان داده میشود و نقاط داده ای که در نزدیکی این بردارها قرار دارند به خوشه های مربوطه اختصاص داده میشوند. این گروه از روش های خوشه ای با استفاده از معیارهای مختلف فاصله، فاصله بین خوشه ها و مرکز را مشخص میکنند. اینها یا مسافت اقلیدسی، فاصله منهتن یا مسافت مینکوفسکی هستند.
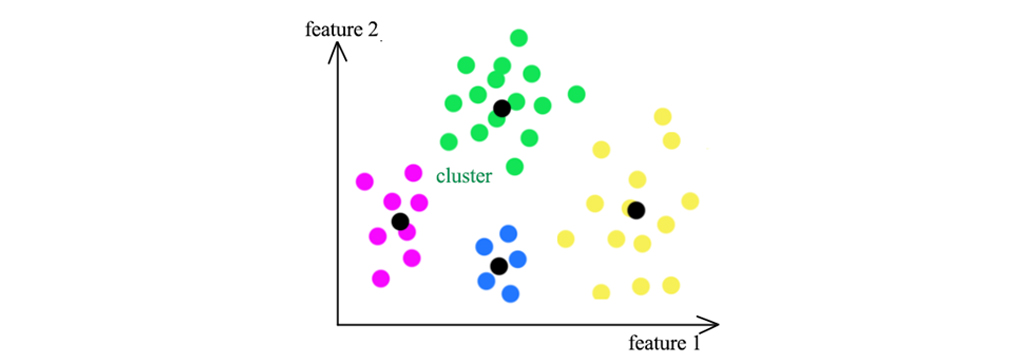
با وجود نقص، خوشه بندی مبتنی بر Centroid ثابت کرده است که ارزش کار خوشه بندی سلسله مراتبی هنگام کار با مجموعه داده های بزرگ است. همچنین، به دلیل سادگی در اجرا و همچنین تفسیر، این الگوریتمها دارای زمینه های کاربردی گسترده ای هستند، یعنی تقسیم بازار، تقسیم بندی مشتری، بازیابی موضوع متن، تقسیم تصویر و غیره است.
خوشه بندی مبتنی بر تراکم (روش های مبتنی بر مدل)
اگر کسی دو روش قبلی را که مورد بحث قرار گرفتیم بررسی کند، مشاهده میکند که هر دو الگوریتم سلسله مراتبی و مرکز محور به یک معیار فاصله (شباهت / مجاورت) وابسته هستند و تعریف کلاستر بر اساس این معیار است. روش های خوشه بندی مبتنی بر تراکم به جای مسافت، تراکم را در نظر میگیرند. خوشه ها به عنوان متراکم ترین ناحیه در یک فضای داده در نظر گرفته میشوند که با نواحی با چگالی کمتر داده جدا شده و به عنوان مجموعه ای با حداکثر نقاط متصل تعریف شده است. هنگام انجام مراحل خوشه بندی، ما دو فرض عمده را در نظر میگیریم، یكی داده ها فاقد هرگونه نویز و دوم این که شكل خوشه ای كه بدین ترتیب ساخته شده است كاملاً هندسی (دایره ای یا بیضوی) است. واقعیت این است که داده ها همیشه دارای نوعی ناسازگاری (نویز) هستند که نمیتوان از آنها چشم پوشی کرد.
علاوه بر این، ما نباید خود را به یک شکل ویژگی ثابت محدود کنیم، مطلوب است که اشکال دلخواه داشته باشیم تا از هیچ نقطه داده ای غافل نشویم. اینها مناطقی هستند که الگوریتم های مبتنی بر تراکم ارزش خود را ثابت کرده اند! الگوریتم های مبتنی بر تراکم میتوانند خوشه هایی با اشکال دلخواه، خوشه های بدون هیچ محدودیتی در اندازه خوشه ها، خوشه هایی با حداکثر سطح همگنی با اطمینان از همان سطح چگالی درون آن بدست آورند و همچنین این خوشه ها شامل نقاط پرت یا داده های پر نویز هستند.
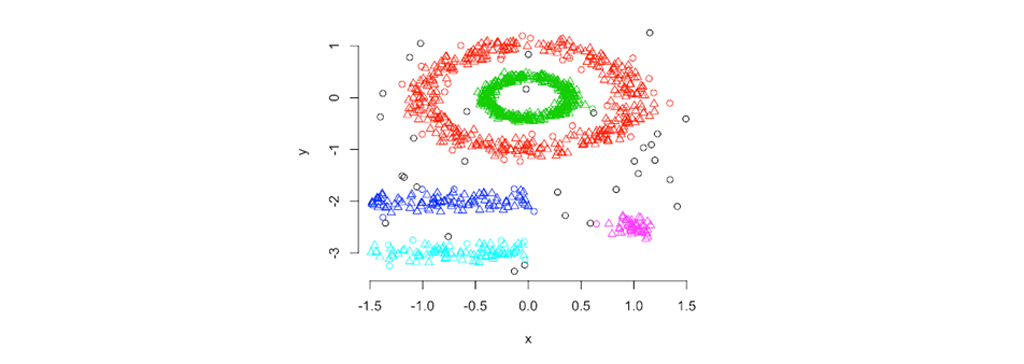
خوشه بندی مبتنی بر توزیع
این یک مدل خوشه بندی است که در آن ما داده ها را بر اساس احتمال اینکه چگونه ممکن است به یک توزیع یکسان تعلق داشته باشند، در گروه های مختلف قرار میدهیم. گروهبندی انجام شده ممکن است معمولی یا گاوسی باشد. مدل های توزیع خوشه بندی بیشترین ارتباط را با آمار دارند. سپس میتوان خوشه ها را به راحتی اشیایی تعریف کرد که به احتمال زیاد به یک توزیع مشابه تعلق دارند.
این مدل روی داده های مصنوعی و خوشه هایی با اندازه های مختلف خوب کار میکند. خوشه بندی مبتنی بر توزیع از نظر انعطاف پذیری، درستی و شکل خوشه های تشکیل شده دارای یک مزیت آشکار نسبت به روش های خوشه بندی مبتنی بر مرکز است. مشکل اصلی این است که این روش های خوشه بندی فقط با داده های مصنوعی یا شبیه سازی شده یا داده هایی که بیشترین نقاط داده مطمئناً به یک توزیع از پیش تعریف شده تعلق دارند، کار میکنند، در غیر این صورت، ممکن است که نتایج با خطا رو به رو باشد.
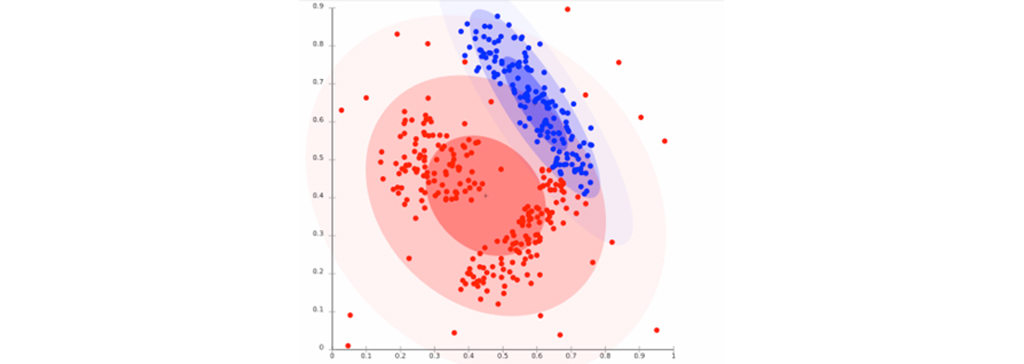
خوشه بندی فازی
ایده کلی خوشه بندی فازی در مورد خوشه بندی مربوط به اختصاص نقاط داده به خوشه های متغیر است، به این معنی که یک نقطه داده همیشه به طور منحصر به فرد در داخل یک خوشه قرار دارد و نمیتواند به بیش از یک خوشه تعلق داشته باشد. روش های خوشه بندی فازی با اختصاص یک نقطه داده به چند خوشه با درجه کمی از معیار تعلق، این الگوی را تغییر میدهند. نقاط داده ای که در نزدیکی مرکز یک خوشه قرار دارند نیز ممکن است در خوشه ای قرار داشته باشند که در درجه بالاتر از نقاط لبه خوشه قرار داشته باشد. امکان متعلق بودن یک عنصر به یک خوشه معین با ضریب عضویت که از 0 تا 1 متغیر است اندازه گیری میشود. خوشه بندی فازی را میتوان برای مجموعه داده هایی استفاده کرد که متغیرها، سطح بالایی از همپوشانی دارند. این یک الگوریتم کاملاً برگزیده برای تقسیم بندی تصویر است، به ویژه در بیوانفورماتیک که شناسایی کدهای ژنی با هم تداخل دارند.
خوشه بندی مبتنی بر محدودیت
خوشه بندی مبتنی بر محدودیت (خوشه نظارت شده) فرآیند خوشه بندی، به طور کلی، براساس این رویکرد است که داده ها را میتوان به تعداد مطلوب گروه های “ناشناخته” تقسیم کرد. مراحل اساسی همه الگوریتم های خوشه بندی برای یافتن آن الگوها و شباهت های پنهان، بدون هیچ گونه مداخله یا شرایط از پیش تعیین شده است؛ با این حال، در برخی از سناریوهای تجاری، ممکن است لازم باشد داده ها را بر اساس محدودیت های خاص تقسیم کنیم. در الگوریتم یک نسخه نظارت شده از تکنیک های یادگیری ماشین خوشه ای است. یک محدودیت به عنوان خصوصیات مطلوب نتایج خوشه بندی یا انتظار کاربر از خوشه های تشکیل شده تعریف میشود – این میتواند از نظر تعداد مشخصی خوشه یا اندازه خوشه یا ابعاد مهم (متغیرها) باشد- که برای فرآیند خوشه بندی مورد نیاز است.
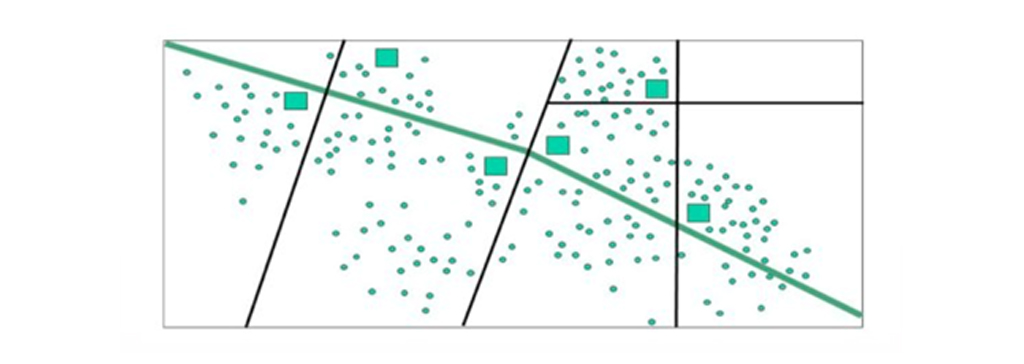
جمع بندی خوشه بندی
خوشه بندی نوعی روش یادگیری بدون نظارت در یادگیری ماشین است. در روش یادگیری بدون نظارت، نمونه ها از مجموعه داده های بدون برچسب گرفته میشود. این یک تکنیک تجزیه و تحلیل داده های اکتشافی است که به ما امکان تجزیه و تحلیل مجموعه داده های چند متغیره را میدهد. خوشه بندی وظیفه ای است که مجموعه داده ها را به تعداد مشخصی از خوشه ها تقسیم میکند به گونه ای که نقاط داده متعلق به یک خوشه دارای ویژگی های مشابه هستند.
خوشه ها چیزی نیستند جز گروه بندی نقاط داده به گونه ای که فاصله بین نقاط داده در خوشه ها حداقل باشد یا به عبارت دیگر، خوشه ها مناطقی هستند که تراکم نقاط داده مشابه زیاد است. خوشه بندی یکی از پرکاربردترین الگوریتمهای یادگیری ماشین است و برای کشف اطلاعات پنهان در داده ها بسیار مورد استفاده قرار میگیرد و میتواند به انسان و ماشین برای حل بسیاری از مشکلات در ابعاد بالا کمک کند.
نویسنده: تیم پژوهش راهبرد
منابع
analytixlabs.co.in/blog/types-of-clustering-algorithms
upgrad.com/blog/clustering-and-types-of-clustering-methods




دیدگاهتان را بنویسید