يادگیری گروهی ensemble learning
سرفصل مطالب
مقدمه ای بر يادگیری گروهی ensemble learning :
يادگیری گروهی یا یادگیری ترکیبی ensemble learning : اصل “خرد جمعیت” نشان می دهد که گروه بزرگی از افراد با دانش متوسط در مورد یک موضوع می توانند به سوالاتی مانند پیش بینی کمیت، استدلال فضایی و دانش عمومی پاسخ های قابل اعتماد ارائه دهند. نتایج کلی، نویز ها را حذف می کند و اغلب می تواند برتر از متخصصان با تجربه باشد. همین قانون می تواند در مورد برنامه های هوش مصنوعی که بر یادگیری ماشین متکی هستند( شاخه ای از هوش مصنوعی که نتایج را بر اساس مدل های ریاضی پیش بینی می کند) اعمال شود. در یادگیری ماشین، خرد جمعی از طریق يادگیری گروهی به دست می آید. برای بسیاری از مشکلات، نتیجه به دست آمده از یک گروه، ترکیبی از مدل های یادگیری ماشین، می تواند دقیق تر از هر یک از اعضای گروه باشد. يادگیری گروهی با ترکیب چند مدل به بهبود نتایج یادگیری ماشین کمک می کند. این رویکرد به شما امکان می دهد عملکرد پیش بینی بهتری را در مقایسه با یک مدل واحد تولید کنید.

يادگیری گروهی یا یادگیری ترکیبی (Ensemble learning)
يادگیری گروهی یا یادگیری ترکیبی : تصور کنید که شما می خواهید یک مدل یادگیری ماشین بسازید که سفارشات موجودی انبار را برای شرکت شما بر اساس داده های تاریخی که از سال های گذشته جمع آوری کرده اید پیش بینی کند. شما از چهار مدل یادگیری ماشین با استفاده از الگوریتم های مختلف استفاده می کنید: رگرسیون خطی، ماشین بردار پشتیبان، درخت تصمیم و یک شبکه عصبی مصنوعی اساسی. اما حتی پس از اصلاح و پیکربندی زیاد، هیچ یک از این الگوریتم ها به 95 درصد دقت پیش بینی مورد نظر شما نمی رسند. این مدل های یادگیری ماشین “یادگیرندگان ضعیف” نامیده می شوند زیرا در سطح مطلوب همگرا نمی شوند.
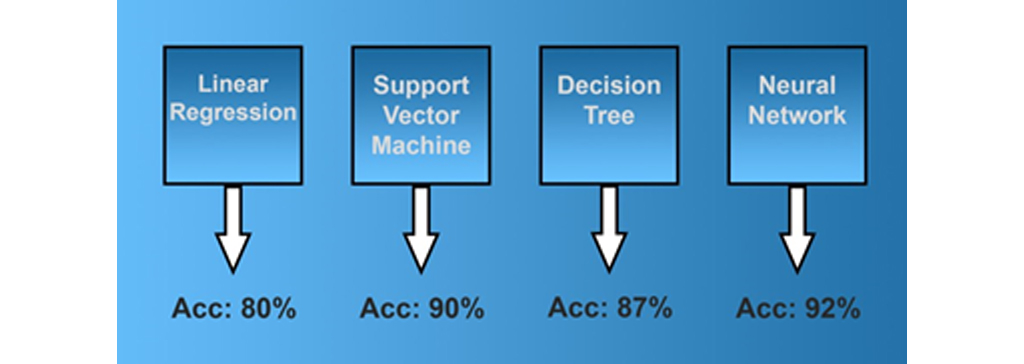
اما ضعیف به معنی بی فایده بودن نیست. می توانید این الگوریتم ها را در یک مجموعه ترکیب کنید. برای هر پیش بینی جدید، داده های ورودی خود را از طریق هر چهار مدل اجرا می کنید و سپس میانگین نتایج را محاسبه می کنید. هنگام بررسی نتیجه جدید، می بینید که نتایج کلی 96 درصد دقت ارائه می دهد، که بیش از حد قابل قبول است. دلیل کارآمدی يادگیری گروهی این است که مدل های یادگیری ماشین شما متفاوت عمل می کنند. هر مدل ممکن است در برخی از داده ها به خوبی و در برخی دیگر دقت کمتری داشته باشد. وقتی همه آن ها را ترکیب کنید، نقاط ضعف یکدیگر را برطرف می کند.
شما می توانید روش های مجموعه ای را برای مشکلات پیش بینی، مانند پیش بینی موجودی که به تازگی مشاهده کردیم و مشکلات طبقه بندی، مانند تعیین اینکه آیا یک تصویر حاوی یک شیء خاص است یا نه، اعمال کنید.
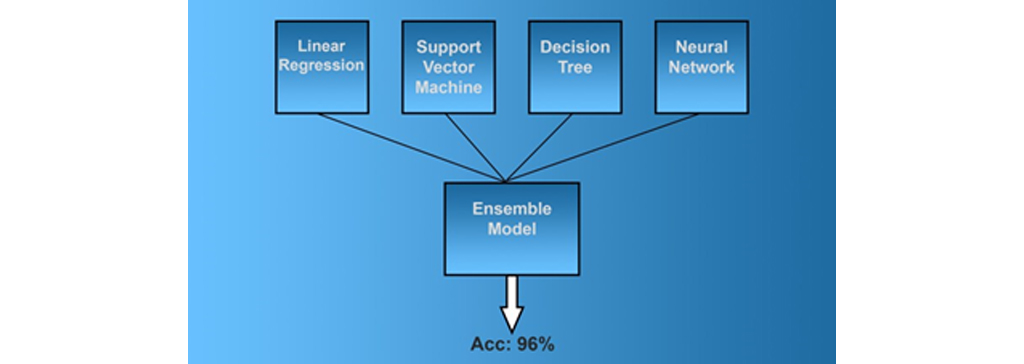
روش های گروهی برای یک گروه یادگیری ماشین، باید مطمئن شوید که مدل های شما از یکدیگر مستقل هستند (یا تا حد ممکن مستقل از یکدیگر). یکی از راه های این کار ایجاد گروه از خود الگوریتم های مختلف است، مانند مثال بالا. روش دیگر استفاده از نمونه های الگوریتم های یادگیری ماشین مشابه و آموزش آنها بر روی مجموعه داده های مختلف است. به عنوان مثال، می توانید مجموعه ای متشکل از 12 مدل رگرسیون خطی ایجاد کنید که هر کدام بر روی زیرمجموعه ای از داده های آموزشی شما آموزش دیده اند.
روش های نمونه برداری از داده های آموزشی
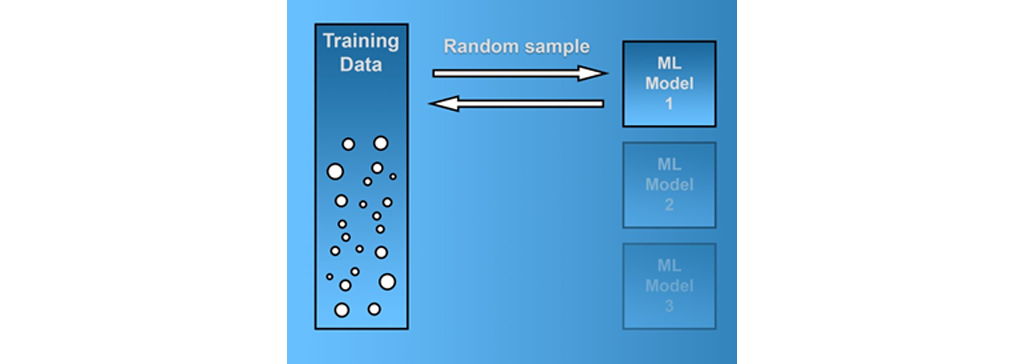
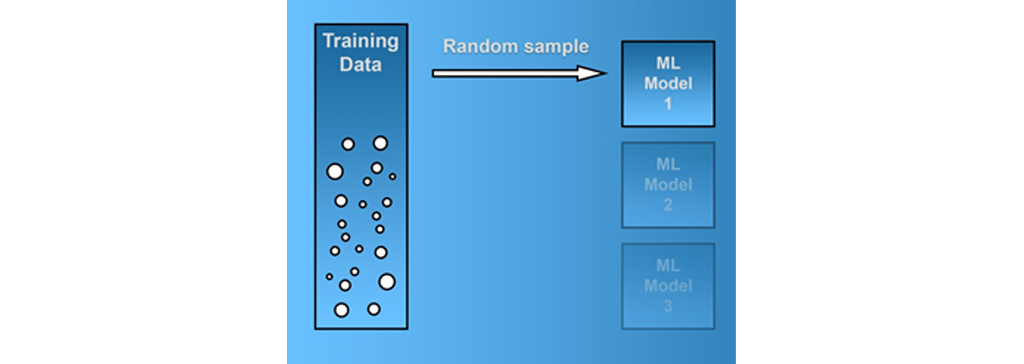
روش های نمونه برداری از داده های آموزشی: دو روش کلیدی برای نمونه برداری از داده های مجموعه آموزشی شما وجود دارد. ” Bootstrap aggregation ” ، معروف به ” bagging ” ، نمونه های تصادفی از مجموعه آموزشی “با جایگزینی” می گیرد. روش دیگر ” pasting “، نمونه ها را “بدون جایگزینی” می گیرد.
برای درک تفاوت بین روش های نمونه گیری، در اینجا یک مثال آورده شده است. بگویید یک مجموعه آموزشی با 10000 نمونه دارید و می خواهید هر مدل یادگیری ماشین را در گروه خود با 9000 نمونه آموزش دهید. در صورت استفاده از bagging ، برای هر یک از مدل های یادگیری ماشین خود، مراحل زیر را انجام دهید:
یک نمونه تصادفی از مجموعه آموزشی ایجاد کنید.
یک کپی از نمونه را به مجموعه آموزشی مدل اضافه کنید.
نمونه را به مجموعه آموزشی اصلی باز گردانید.
این روند را 8999 بار تکرار کنید.
هنگام استفاده از pasting ، شما همین روند را طی می کنید، با این تفاوت که نمونه ها پس از کشیدن به مجموعه آموزشی بازگردانده نمی شوند. در نتیجه، همان نمونه ممکن است چندین بار هنگام استفاده از bagging در مدل ظاهر شود، اما فقط یک بار هنگام استفاده از pasting در آموزش به کار می رود. پس از آموزش تمام مدل های یادگیری ماشین، باید روش تجمیع را انتخاب کنید.
روش های Boosting
یکی دیگر از تکنیک های محبوب گروه بندی” Boosting ” است. برخلاف روش های کلاسیک گروهی، که در آن مدل های یادگیری ماشین به طور موازی آموزش داده می شوند، روش های Boosting مدل را به صورت متوالی آموزش می دهد و هر مدل جدید بر مدل قبلی تکیه می کند و ناکارآمدی های خود را برطرف می کند. (AdaBoost) مخفف “تطبیق پذیری” ، یکی از محبوب ترین روش های تقویت کننده است، با تطبیق مدل های جدید با اشتباهات مدل های قبلی، دقت مدل های مجموعه را افزایش می دهد. پس از آموزش اولین مدل یادگیری ماشین خود، نمونه های آموزشی را که توسط مدل اشتباه طبقه بندی شده یا به اشتباه پیش بینی شده است، مشخص می شود.
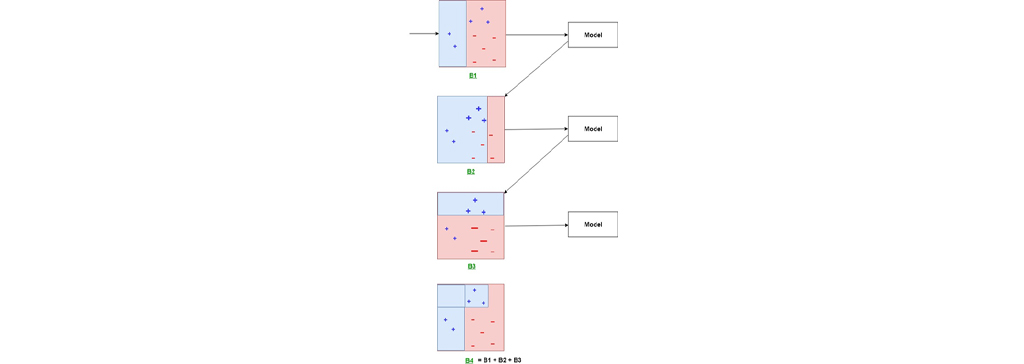
هنگام آموزش مدل بعدی، بر این مثال ها بیشتر تأکید می شود. این امر منجر به یک مدل یادگیری ماشین می شود که در جایی که مدل قبلی شکست خورده بهتر عمل می کند. این روند برای تعداد زیادی از مدل هایی که می خواهید به مجموعه اضافه کنید تکرار می شود. مجموعه نهایی شامل چندین مدل یادگیری ماشین با دقت های مختلف است که با هم می توانند دقت بهتری را ارائه دهند. در مجموعه های تقویت شده، به خروجی هر مدل وزنی متناسب با دقت آن داده می شود. در شکل زیر شمای کلی این روش را مشاهده می کنید. علامت های مثبت و منفی در شکل لیبل های پیش بینی شده مدل برای داده های آموزشی است.
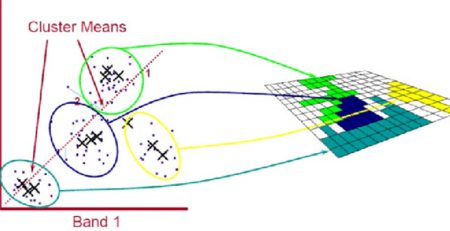
جنگل های تصادفی
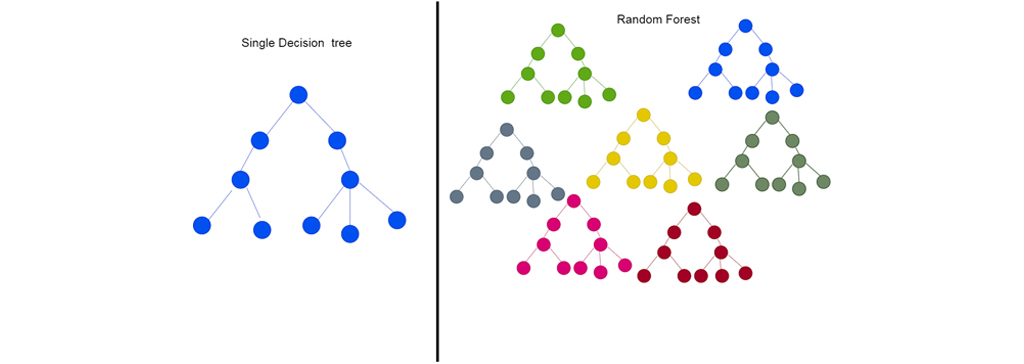
یکی از زمینه هایی که در يادگیری گروهی بسیار محبوب است درخت تصمیم گیری است، یک الگوریتم یادگیری ماشین که به دلیل انعطاف پذیری و تفسیرپذیری بسیار مفید است. درختان تصمیم گیری می توانند در مورد مشکلات پیچیده پیش بینی کنند و همچنین می توانند خروجی های خود را در مجموعه ای از مراحل بسیار روشن دنبال کنند. مشکل درختان تصمیم گیری این است که آن ها بین کلاس های مختلف مرزهای صاف ایجاد نمی کنند مگر اینکه آن ها را به شاخه های زیادی تقسیم کنند، در این صورت آن ها مستعد “” overfitting می شوند، این مشکل زمانی به وجود می آید که یک مدل یادگیری ماشین در مورد داده های آموزشی بسیار خوب عمل می کند. اما در مورد نمونه های جدید از دنیای واقعی ضعیف عمل می کند. این مشکلی است که می توان با يادگیری گروهی حل کرد. جنگل های تصادفی مجموعه های یادگیری ماشین هستند که از درختان تصمیم گیری متعدد تشکیل شده اند. استفاده از جنگل های تصادفی این اطمینان را می دهد که یک مدل یادگیری ماشین در محدوده های خاص یک درخت تصمیم گیر نمی کند. در سمت راست تصویر مسئله با تشکیل یک درخت حل شده است و در سمت چپ مسئله با ایجاد چندین درخت حل می شود.
مشکلات یادگیری گروهی
مشکلات يادگیری گروهی : در حالی که یادگیری گروهی یک ابزار بسیار قدرتمند است، اما برخی محدودیت هایی نیز دارد. استفاده از مجموعه به این معنی است که شما باید زمان و منابع بیشتری را برای آموزش مدل های یادگیری ماشین خود صرف کنید. به عنوان مثال، یک جنگل تصادفی با 500 درخت نتایج بسیار بهتری را نسبت به یک درخت تصمیم واحد ارائه می دهد، اما آموزش آن نیز زمان بیشتری می برد. اگر الگوریتم هایی که استفاده می کنید به حافظه زیادی نیاز دارند، اجرای مدل های گروهی نیز می تواند مشکل ساز شود.
یکی دیگر از مشکلات یادگیری گروهی توضیح پذیری است. در حالی که افزودن مدل های جدید به یک مجموعه می تواند دقت کلی آن را بهبود بخشد، بررسی تصمیمات اتخاذ شده توسط الگوریتم هوش مصنوعی را دشوارتر می کند. ردیابی یک مدل یادگیری ماشین مانند درخت تصمیم گیری آسان است، اما وقتی صدها مدل را در یک خروجی شرکت دهید، بررسی منطقی بودن هر تصمیم را بسیار دشوارتر می کند.
کاربرد های یادگیری جمعی
از کاربرد های یادگیری جمعی می توان به موارد زیر اشاره کرد:
امنیت رایانه
حملات به سیستم های توزیع شده خدمات یکی از تهدید کننده ترین حملات سایبری است که ممکن است برای یک ارائه دهنده خدمات اینترنتی اتفاق بیفتد. با ترکیب خروجی طبقه بندی کننده های واحد، طبقه بندی کننده های گروهی خطای کلی تشخیص چنین حملاتی را از سوی خرابکاران کاهش می دهد.
تشخیص بدافزار
کدهای بدافزار مانند ویروس های رایانه ای، کرم های رایانه ای، تروجان ها، باج افزارها و جاسوس افزارها با استفاده از تکنیک های یادگیری ماشین، از مشکلات موجود در سیستم های طبقه بندی الهام گرفته شده است. سیستم های یادگیری مجموعه ای در این زمینه کارآیی مناسبی را نشان داده اند.
تشخیص نفوذ به سیستم
یک سیستم تشخیص نفوذ شبکه های کامپیوتری یا سیستم های رایانه ای را تحت نظر دارد تا کدهای مزاحم را مانند یک فرایند تشخیص ناهنجاری شناسایی کند. یادگیری گروهی با موفقیت به چنین سیستم های نظارتی کمک می کند تا خطای کلی آنها را کاهش دهد.
تشخیص چهره
تشخیص چهره، که اخیراً به یکی از محبوب ترین زمینه های تحقیقاتی در زمینه تشخیص الگو تبدیل شده است، با شناسایی یا تأیید افراد با تصاویر دیجیتالی کار می کند. مجموعه های سلسله مراتبی مبتنی بر طبقه بندی Gabor Fisher و تکنیک های پیش پردازش تجزیه و تحلیل مولفه های مستقل برخی از اولین مجموعه هایی هستند که در این زمینه استفاده می شوند.
تشخیص احساسات
تشخیص احساسات در حالی که تشخیص گفتار عمدتا مبتنی بر یادگیری عمیق است زیرا اکثر بازیگران صنعت در این زمینه مانند Google ، Microsoft و IBM نشان می دهند که فناوری اصلی تشخیص گفتار آنها بر اساس این رویکرد است، تشخیص احساسات مبتنی بر گفتار نیز می تواند عملکرد رضایت بخشی داشته باشد. يادگیری گروهی همچنین با موفقیت در تشخیص احساسات صورت استفاده می شود.
تشخیص تقلب
کشف کلاهبرداری با شناسایی کلاهبرداری بانکی مانند پولشویی، کلاهبرداری از کارت اعتباری و کلاهبرداری از راه دور، که دارای حوزه های وسیع تحقیق و کاربردهای یادگیری ماشین است، سروکار دارد. از آنجا که يادگیری گروهی استحکام مدل سازی رفتار عادی را بهبود می بخشد، به عنوان یک تکنیک کارآمد برای تشخیص چنین موارد و فعالیت های کلاهبرداری در سیستم های بانکی و کارت اعتباری پیشنهاد شده است.
تصمیم گیری مالی
صحت پیش بینی شکست کسب و کار یک مسئله بسیار مهم در تصمیم گیری های مالی است. بنابراین، طبقه بندی کننده های مختلف گروهی برای پیش بینی بحران های مالی و مشکلات مالی پیشنهاد می شوند. همچنین، در مشکلاتی مانند این که معامله گران سعی می کنند قیمت سهام را با خرید و فروش فعالیت ها دستکاری کنند، طبقه بندی کننده های گروهی موظف هستند تغییرات بازار سهام را تجزیه و تحلیل کنند. داده ها و علائم مشکوک دستکاری قیمت سهام را تشخیص دهد.
جمع بندی يادگیری گروهی یا یادگیری ترکیبی یا یادگیری جمعی یا ensemble learning
يادگیری گروهی یا یادگیری ترکیبی یا یادگیری جمعی یا ensemble learning : هدف از هر مشکل یادگیری ماشین یافتن یک مدل واحد است که بهترین نتیجه مورد نظر ما را پیش بینی کند. به جای ساختن یک مدل و امیدوار بودن به این مدل بهتر است که بهترین مدل و دقیق ترین مدل پیش بینی کننده ای را که می توانیم داشته باشیم، بسازیم. روش های مجموعه ای یا گروهی بی شمار مدل را در نظر می گیرند و برای تولید یک مدل نهایی از این مدل ها میانگین یا رای می گیرند. علاوه بر روش های مورد مطالعه در این مطلب، استفاده از مجموعه ها در یادگیری عمیق با آموزش طبقه بندی کننده های متنوع و دقیق متداول است. تنوع را می توان با معماری های مختلف، تنظیمات فوق پارامترها و تکنیک های آموزشی به دست آورد. روش های گروهی در ثبت عملکرد ضعیف در مجموعه داده های چالش برانگیز بسیار موفق است.
نویسنده: تیم پژوهش راهبرد
منابع
bdtechtalks.com
blog.statsbot.co
دیدگاهتان را بنویسید