الگوریتم پس انتشار خطا یا الگوریتم Backpropagation
سرفصل مطالب
الگوریتم پس انتشار خطا یا الگوریتم Backpropagation
الگوریتم پس انتشار خطا یا الگوریتم Backpropagation یک ابزار یا الگوریتم ضروری برای بهبود مواردی است که با نتایج ضعیف از یادگیری ماشین و داده کاوی مواجه می شوید. هنگامی که داده های زیادی را به سیستم ارائه می دهید و راه حل های صحیح را با مدلی مانند شبکه های عصبی مصنوعی ایجاد می کنید، سیستم داده ها، را تعمیم داده و جستجوی داده ها را آغاز می کند. به عنوان مثال، در تصویربرداری، سیستمی می سازید که از اشتباهات خود درس می گیرد و پس از انجام ندادن عملکردها، عملکردش را بهبود می بخشد. سیستم راه حل را ارائه می دهد و در صورت شکست، راه حل دیگری را برای مشکل به تنهایی حدس می زند. با این حال، آموزش چنین سیستم هایی زمان زیادی را می طلبد زیرا الگوریتم پس انتشار خطا، خروجی شبکه را بر روی درخت عرضی ایجاد می کند و داده ها را ساختار می بخشد. رایج ترین استفاده از Backpropagation در یادگیری ماشین برای آموزش شبکه های عصبی مصنوعی است. این الگوریتم با تغییر وزن در هر خطا از گرادیان کاهشی برای فرآیند یادگیری استفاده می کند.
الگوریتم پس انتشار خطا چیست؟
الگوریتم پس انتشار خطا چیست؟ الگوریتم Backpropagation یک ابزار یا الگوریتم ضروری برای بهبود مواردی است که که نتایج ضعیف از آموزش شبکه عصبی مصنوعی حاصل شده است. الگوریتم پس انتشار خطا اساسی ترین بلوک ساختمان در یک شبکه عصبی است. برای اولین بار در 1960 بیان شد و تقریبا 30 سال بعد (1989) توسط Rumelhart ، Hinton و Williams در مقاله ای با عنوان “یادگیری بازنمایی ها با انتشار اشتباهات” انتشار یافت. این الگوریتم برای آموزش موثر شبکه عصبی از طریق روشی به نام قاعده زنجیره استفاده می کند. به زبان ساده، پس از عبور هر گام شبکه عصبی، الگوریتم backpropagation برای تنظیم پارامترهای مدل (وزن و بایاس)، یک گام به عقب بر می گردد.
شبکه های عصبی مصنوعی
همانطور که الگوریتم Backpropagation با در نظر گرفتن عملکرد مغز انسان ایجاد شد، شبکه های عصبی مصنوعی شبیه سیستم عصبی مغز هستند. این روند یادگیری را سریع و کارآمد می کند. یک نورون مصنوعی تنها یک سیگنال دریافت می کند و پس از پردازش و آموزش آن را به سایر نورون های پنهان، منتقل می کند. وزن های متفاوتی در اتصال یک نورون به نورون دیگر وجود دارد. اتصالات به عنوان لبه نیز شناخته می شوند. افزایش و کاهش وزن باعث تغییر در قدرت سیگنال ها می شود. سپس سیگنال به نورون های خروجی منتقل می شود. این نورون های مصنوعی به عنوان شبکه های پیشرو نیز شناخته می شوند.
عملکرد الگوریتم پس انتشار خطا
عملکرد الگوریتم پس انتشار خطا: الگوریتم Backpropagation به آموزش شبکه های عصبی مصنوعی کمک می کند. عملکرد شبکه های عصبی بر پایه تکرار است. یکی از الگوریتم های پر کاربرد در این زمینه الگوریتم پس انتشار خطا است. با به کار بردن این الگوریتم در هر تکرار دو مرحله خواهیم داشت مرحله اول هنگامی که شبکه های عصبی مصنوعی شکل می گیرند، مقادیر وزن ها به صورت تصادفی تعیین می شوند. کاربر وزن های تصادفی را تعیین می کند زیرا از مقادیر صحیح آگاه نیست. پس از تعیین وزن ها، سپس حرکت رو به جلو (feed forward) را خواهیم داشت. در این قسمت با انجام عملیات ضرب داده های ورودی در وزن ها و سپس جمع کردن آن با بایاس شبکه پیش می رود. نهایتاً در همان مرحلهی به یک مقدار خروجی خواهیم رسید که ممکن است با خروجی واقعی اختلاف داشته باشد.
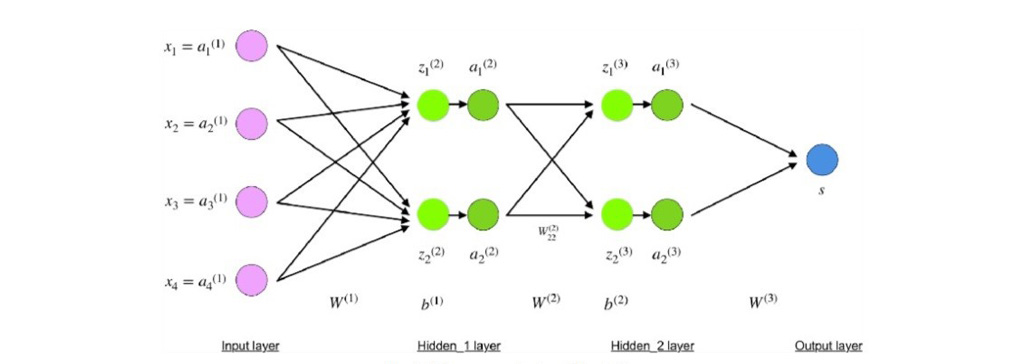
بعد از این که شبکه متوجه خطا با توجه به وزن ها و بایاس شد وارد قسمت دوم این مرحله می شویم. در این قسمت شبکه به عقب بر می گردد و به طور مجدد وزن ها و بایاس را محاسبه می کند. این تغییر به سمتی پیش می رود که میزان خطا کاهش یابد و مقدار پیش بینی شده با مقدار واقعی تفاوت کمتری داشته باشد.
نکته: هنگامی که مقادیر متفاوتی از شبکه عصبی مورد انتظار است، شبکه این اختلاف را به عنوان خطا در نظر می گیرد. الگوریتم به گونه ای تنظیم شده است که هر بار که خروجی مورد انتظار نیست، مدل پارامترها را تغییر می دهد. این خطا با شبکه های عصبی مصنوعی ارتباط دارد. بنابراین وقتی پارامتر تغییر می کند، خطا نیز تغییر می کند تا زمانی که شبکه عصبی با محاسبه گرادیان کاهشی خروجی مورد نظر را پیدا کند.
اهمیت الگوریتم پس انتشار خطا
اهمیت الگوریتم پس انتشار خطا: تا اینجا متوجه شدیم با اجرای شبکه عصبی ممکن است مقادیر به عنوان خروجی دریافت کنیم که با خطا مواجه باشد. بنابراین برای رفع این خطا از الگوریتم پس انتشار خطا استفاده می کنیم. در ادامه مطلب به اهمیت استفاده از این الگوریتم می پردازیم. وقتی که قرار است یک شبکه عصبی به طور مثال تفاوت گربه از سگ را تشخیص دهد کار بسیار اسانی است و شبکه با دریافت تعدادی نمونه و ویژگی های آن این کار را انجام می دهد. حالا تصور کنید که یک شبکه عصبی با 2000 (بعد یا ویژگی )نرون داریم و 3 لایه مخفی و همچنین شبکه ی ما دارای 9 لایه خروجی است که قرار است 9 نوع از اشیا را دسته بندی کند. این تعداد نرون بسیار زیاد است. این شبکه بسیار پیچیده است. بنابراین یافتن وزن ها و بایاس اصلاً کار آسانی نیست و بسیار زمان بر است.
مثال الگوریتم پس انتشار خطا
مثال الگوریتم پس انتشار خطا: در ادامه ما یک مثال فرضی ساده شده را می بینیم. پس با راهبرد همراه باشید.
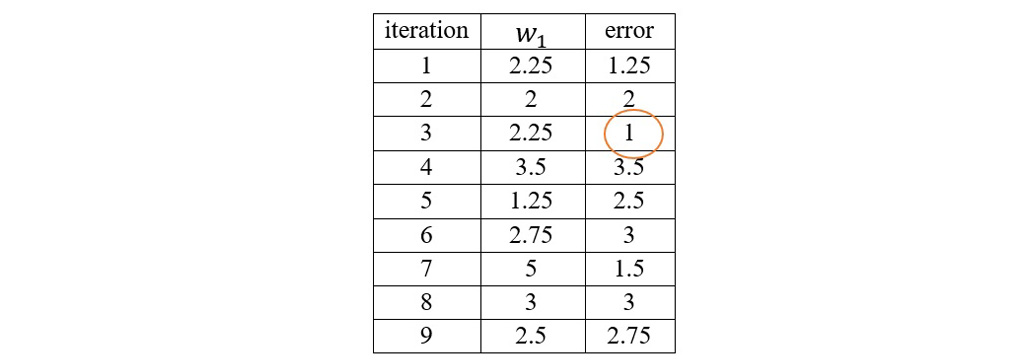
با توجه به جدول بالا کمترین میزان خطا در دور سوم و با وزن 2.25 اتفاق افتاده است. این یک مدل کاملاً ساده است که فقط برای وزن w1 محاسبه شده است. با تغییر یک وزن خطای میانگین کل شبکه ممکن است تغییر کند. شبکه به دنبال یافتن وزن هایی است که بتواند خطا را کاهش دهد.
در یک مثال واقعی که قرار است با شبکه عصبی انجام شود ما تنها یک وزن نداریم، و امکان دارد حدود 2000 وزن داشته باشیم که هر کدام مربوط به یک ویژگی است. یافتن مقدار بهینه برای این وزن ها توسط الگوریتم های عادی زمان بر است. این جا است که الگوریتم پس انتشار خطا وظیفه یافتن وزن های بهینه را در هر لایه دارد و با توجه به مقدار خروجی خطا ی شبکه وزن ها را بهینه می کند.
الگوریتم کاهش گرادیان ( گرادیان کاهشی )
در مثال بالا که بسیار هم ساده شده بود به دنبال کمترین مقدارِ خطا بودیم. با توجه به میزان وزن هایی که در جدول داشتیم کمترین مقدار خطا در وزن 2.25 رخ داده است که این مقدار خطا برابر یک است. اگر فرض کنیم 2000 نرون داریم در هر مرحله باید خطا محاسبه شود و سپس وزن ها آپدیت شود(مثلاً در پردازش یک تصویر باید 1000 یا خیلی بیشتر از این تعداد وزن را آپدیت کرد و تابع خطا را برای هر 1000 وزن محاسبه کرد)و سپس آن را تغییر داد و مجدد تست کرد. روش پیشنهادی برای انجام این عملیات وقت گیر و پر هزینه گرادیان کاهشی است.
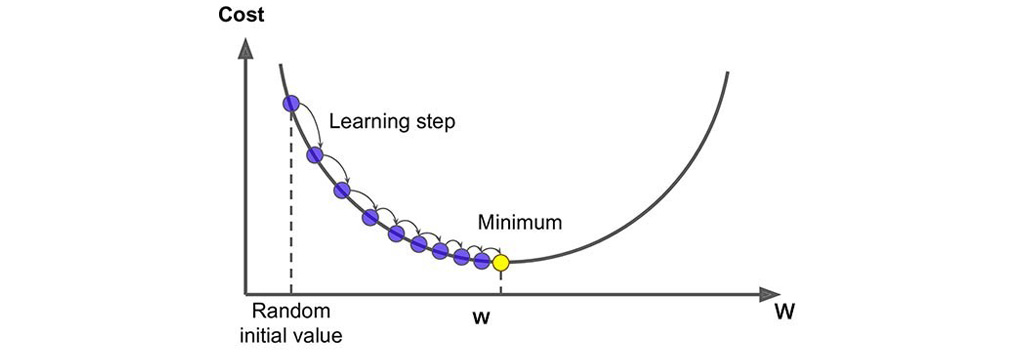
الگوریتم کاهش گرادیان یا الگوریتم گرادیان کاهشی
در الگوریتم کاهش گرادیان یا الگوریتم گرادیان کاهشی برای یافتن مقدار وزن بهینه از قوانین مشتق و خط مماس استفاده میشود. مشتق، شیبِ خطِ مماس بر یک نقطه از یک تابع را نشان می دهد. بر طبق شکل بالا یک نقطه رندوم انتخاب می کنیم و مشتق تابع را در آن نقطه می گیریم. اگر مشتق در آن نقطه منفی شود به این معنی است که خط به سمت پایین است. الگوریتم پس انتشار پس از دیدن خطی با شیب منفی به این نتیجه می رسد که باید مقدار وزن را افزایش دهد تا مقدار مشتق تابع در ان نقطه صفر شود. صفر بودن شیب یعنی کمترین میزان خطا در آن محدوده اتفاق می افتد. در شکل بالا نقطه زرد نشان دهنده شیب صفر است و خطا در کمترین مقدار خود قرار دارد.
کاربرد الگوریتم پس انتشار خطا
الگوریتم پس انتشار خطا به دلیل مزایایی که دارد و اینکه در این الگوریتم تلاش شده که بیشتر کار ها بر عهده سیستم باشد تا کاربرد، کاربرد های بیشماری دارد. از این کاربرد ها می توان به پردازش زبان طبیعی اشاره کرد. امروزه دستیار های هوشمند و همچنین سرچ هایی که با تکیه بر گفتار انجام می شود بسیار زیاد است. پایه اکثر این پردازش ها الگوریتم پس انتشار خطا است.
از دیگر کاربرد های الگوریتم پس انتشار خطا پردازش تصویر است. پردازش تصویر در تکنولوژی خودروهای خود ران و تشخیص چهره و تشخیص هوشمند دست خط و جلوگیری از کلاهبرداری ها بسیار استفاده می شود و به یکی از محبوب ترین روش ها تبدیل شده است.
مزایای الگوریتم پس انتشار خطا
الگوریتم پس انتشار خطا مزایای زیادی دارد. با این حال، در ادامه رایج ترین و برجسته ترین مزایای استفاده از الگوریتم Backpropagation برای یادگیری از خطاهای شبکه عصبی مصنوعی را بررسی می کنیم. به غیر از تصحیح خطوط در وزن و فضای بایاس از طریق گرادیان کاهشی، دلیل دیگری برای افزایش محبوبیت الگوریتم های پس انتشار خطا وجود دارد، که استفاده از شبکه های عصبی عمیق را برای عملکردهایی مانند تشخیص تصویر و تشخیص گفتار است؛ در این عملیات ها این الگوریتم نقش بسیار پر رنگی را ایفا می کند.
- با حذف پیوندهای وزنی، ساختار شبکه را ساده می کند.
- برنامه ریزی سریع و آسان.
- نیازی به دانش قبلی در مورد شبکه ها ندارد.
- نیازی به مشخص کردن ویژگی های تابع برای یادگیری نیست.
- امکان محاسبه کارآمد گرادیان در هر لایه.
معایب الگوریتم پس انتشار خطا
معایب الگوریتم پس انتشار خطا : اگر چه مزایای پس انتشار خطا از معایب آن بیشتر است، اما برجسته کردن این محدودیت ها همچنان ضروری است. بنابراین، در اینجا محدودیت های الگوریتم های پس انتشار خطا را بررسی می کنیم.
- برای انجام یک مشکل خاص، به ورودی متکی است.
- حساس به داده های پیچیده/پر نویز است.
- برای طراحی شبکه به مشتقات توابع فعال سازی نیاز دارد.
نتیجه الگوریتم پس انتشار خطا یا الگوریتم Backpropagation
الگوریتم پس انتشار خطا یا الگوریتم Backpropagation : از بحث فوق مشهود است که انتشار مجدد به بخشی جدایی ناپذیر از شبکه های عصبی تبدیل شده است، زیرا شبکه های عصبی بر این الگوریتم تکیه می کند تا خودکفا شود و بتواند مشکلات و مسائل پیچیده را مدیریت کند. علاوه بر این، به شبکه های عصبی امکان یادگیری دقیق در عین انعطاف پذیری را ارائه می دهد. در حال حاضر، محبوبیت این الگوریتم به حدی است که جدیدترین فناوری ها مانند پردازش زبان طبیعی، تشخیص گفتار، تشخیص تصویر و موارد دیگر از آن برای انجام موفقیت آمیز وظایف تعیین شده خود استفاده می کنند.
نویسنده: تیم پژوهش راهبرد


دیدگاهتان را بنویسید