الگوریتم جنگل تصادفی Random Forest
سرفصل مطالب
مقدمه الگوریتم جنگل تصادفی Random Forest
الگوریتم جنگل تصادفی Random Forest یک الگوریتم محبوب یادگیری ماشین از زیرمجموعه هوش مصنوعی است که به تکنیک یادگیری نظارت شده تعلق دارد. میتواند برای مشکلات طبقه بندی و رگرسیون (پیشبینی و بیان تغییرات یک متغییر بر اساس اطلاعات متغییر دیگر) در یادگیری ماشین استفاده شود. این مبتنی بر مفهوم یادگیری گروه است، که یک فرآیند ترکیب چندین طبقه بندی کننده برای حل یک مسئله پیچیده و بهبود عملکرد مدل است.
همانطور که از نام این الگوریتم پیداست، الگوریتم جنگل تصادفی Random Forest یک طبقه بندی است که شامل تعدادی درخت تصمیم در زیرمجموعه های مختلف مجموعه داده قرار دارد و برای بهبود دقت پیشبینی آن مجموعه داده، میانگین میگیرد. جنگل تصادفی به جای تکیه بر یک درخت تصمیم، پیشبینی را از هر درخت و براساس اکثریت آرا پیش بینی میکند و نتیجه نهایی را به عنوان خروجی در نظر میگیرد. تعداد بیشتر درختان در جنگل منجر به دقت بالاتری میشود و از بروز مشکل Overfitting جلوگیری میکند.

جنگل تصادفی Random Forest
اکثر افراد باید حداقل یک بار با مسئله ی احتمالی برخورد کرده باشند که قرار بوده در آن با توجه به تعداد توپهای هر رنگ، یک توپ رنگی خاص از کیسه ای حاوی توپهای رنگی مختلف بدست آورند. جنگلهای تصادفی ساده هستند اگر بخواهیم آنها را با این قیاس در ذهن بیاموزیم.
جنگل تصادفی Random Forest اساساً مانند کیسه ای است که شامل n درخت تصمیمگیری است که دارای مجموعه ای متفاوت است و در زیر مجموعه های مختلف داده آموزش داده میشود. فرض کنیم در جنگل تصادفی 100 درخت تصمیم داریم !! همانطور که گفتم، این درختان تصمیم دارای مجموعه ای متفاوت از پارامترهای فوق العاده و زیرمجموعه ای از داده های آموزشی متفاوت هستند، بنابراین تصمیم یا پیش بینی ارائه شده توسط این درختان میتواند بسیار متفاوت باشد.
بیایید در نظر بگیریم که به نوعی تمام این 100 درخت را با زیر مجموعه داده های مربوط به آنها آموزش داده ایم. اکنون تمام صد درخت موجود بررسی میشود که پیش بینی آنها در مورد داده های آزمایش چیست. حال باید فقط یک تصمیم در مورد یک مثال یا یک داده آزمون بگیریم، این کار را با رأی گیری ساده انجام میدهیم. ما با آنچه که اکثر درختان برای آن مثال پیشبینی کرده اند را بعوان نتیجه میپذیریم.
طبقه بندی رندوم فارست
الگوریتم جنگل تصادفی Random Forest اساساً یک الگوریتم یادگیری تحت نظارت است. این را میتوان برای کارهای رگرسیون و طبقه بندی هر دو استفاده کرد. اما در این مطلب در مورد کاربرد آن برای طبقه بندی رندوم فارست بحث خواهیم کرد زیرا درک آن بصری تر و آسان تر است. جنگل تصادفی به دلیل سادگی و پایداری یکی از پرکاربردترین الگوریتم هاست. هنگام ساخت زیر مجموعه داده برای درختان، کلمه “تصادفی” به تصویر میآید. زیر مجموعهای از داده ها با انتخاب تصادفی x تعداد ویژگی (ستون) و تعداد y نمونه (ردیف) از مجموعه اصلی n ویژگی و m مثال ساخته میشود.
جنگلهای تصادفی از یک درخت تصمیمگیری پایدارتر و قابل اطمینان ترند. این فقط برداشتی از این جمله است :” بهتر است از همه وزرای کابینه رأی بگیرید تا اینکه فقط تصمیمی که نخست وزیر میگیرد را قبول کنید”. همانطور که دیدیم جنگلهای تصادفی چیزی نیست جز مجموعه ای از درختان تصمیم، بنابراین شناخت درخت تصمیم ضروری میشود.
در ادامه ی مطلب الگوریتم جنگل تصادفی Random Forest را بررسی میکنیم. در دو فاز اول ایجاد جنگل تصادفی با ترکیب N درخت تصمیم و فاز دوم پیش بینی برای هر درخت ایجاد شده در فاز اول است. روند کار را می توان در مراحل و نمودار زیر توضیح داد:
مرحله 1: نقاط تصادفی K داده را از مجموعه آموزش انتخاب کنید.
مرحله 2: درختان تصمیم مرتبط با نقاط داده انتخاب شده (زیرمجموعه ها) را بسازید.
مرحله 3: تعداد N را برای درختان تصمیمی که میخواهید بسازید انتخاب کنید.
مرحله 4: مرحله 1 و 2 را تکرار کنید.
مرحله 5: برای نقاط داده جدید، پیش بینیهای هر درخت تصمیمگیری را پیدا کرده و نقاط داده جدید را به دستهای که آرای اکثریت را کسب میکند، اختصاص دهید.
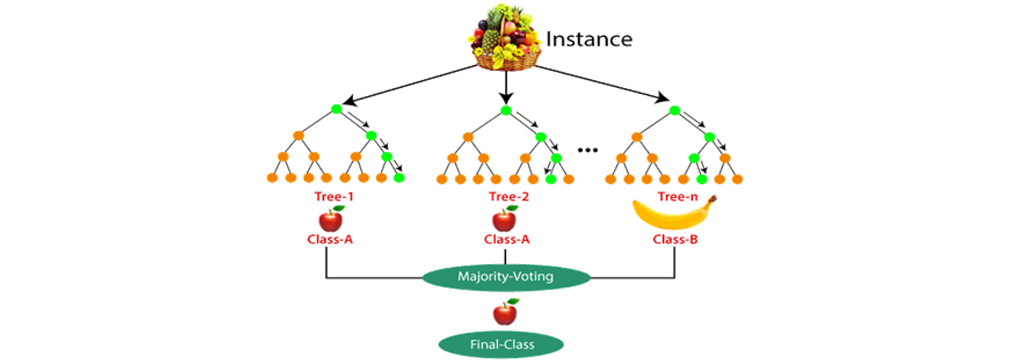
مثال الگوریتم جنگل تصادفی Random Forest
اگر با کلمات بسیار ساده بخواهیم الگوریتم جنگل تصادفی را بیان کنیم، این یک “مجموعه قوانین” است که با یادگیری روی یک مجموعه داده ایجاد میشود و میتواند برای پیش بینی داده های آینده استفاده شود. سعی خواهیم کرد این را با یک مثال الگوریتم جنگل تصادفی Random Forest درک کنیم.
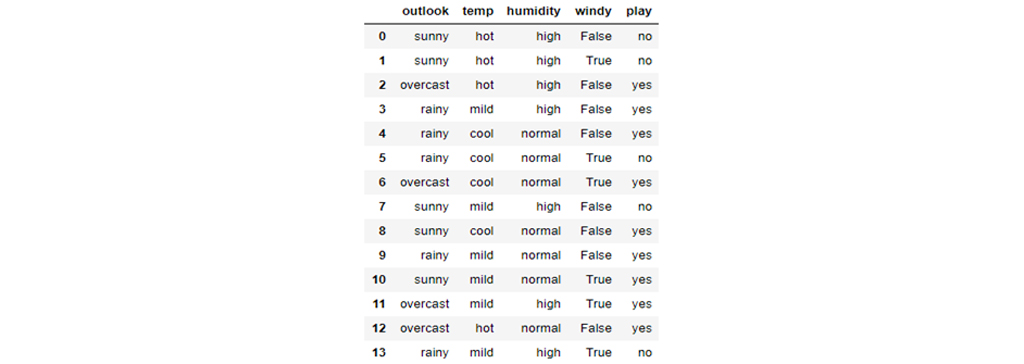
یک مجموعه کوچک ساده در اینجا نشان داده شده است. در این مجموعه داده، چهار ویژگی اول ویژگیهای مستقل و آخرین ویژگی وابسته است. ویژگیهای مستقل وضعیت آب و هوا را در یک روز مشخص توصیف میکنند و ویژگی وابسته نشان میدهد که آیا در آن روز میتوانستیم تنیس بازی کنیم یا خیر. اکنون سعی خواهیم کرد برخی قوانین را با استفاده از ویژگیهای مستقل برای پیش بینی ویژگیهای وابسته ایجاد کنیم. فقط با مشاهده، میبینیم که اگر Outlook ابری باشد، بازی صرف نظر از سایر ویژگیها همیشه بله است. به همین ترتیب می توانیم همه قوانین را برای توصیف کامل مجموعه داده ها ایجاد کنیم. در اینجا تعدادی از قوانین ذکر شده است. قانون شماره ی یک (R1) اگر شرایط افتابی باشد و همچنین رطوبت بالا باشد شرایط برای بازی مناسب نیست و قانون شماره دو (R2) اگر هوا افتابی باشد و رطوبت نرمال شرایط برای بازی مساعد است و به همین ترتیب دیگر قوانین قابل تفسیر هستند.
- R1: If (Outlook=Sunny) AND (Humidity=High) Then Play=No
- R2: If (Outlook=Sunny) AND (Humidity=Normal) Then Play=Yes
- R3: If (Outlook=Overcast) Then Play=Yes
- R4: If (Outlook=Rain) AND (Wind=Strong) Then Play=No
- R5: If (Outlook=Rain) AND (Wind=Weak) Then Pay=Yes
میتوانیم به راحتی این قوانین را به نمودار درختی تبدیل کنیم. این نمودار درختی است. برای ایجاد این درخت هر ویژگی مستقل که در بالای جدول قرار داد به عنوان گره (Node) و مقادیر ستونها به عنوان برگ (Leaf) در نمودار قرار میگیرد. در نمودار درختی ابتدا از اولین ویژگی جدول (outlook) شروع میکنیم و سپس با توجه به مقادیر ستون اول که شامل سه مقدار Rain، Overcast،Sunny میباشد برای هر مقدار یک شاخه ایجاد میشود.
برای شاخه ی Outlook در حالت Overcast دیگر نیازی به در نظر گرفتن دیگر شرایط ندارد چون در هر صورت میتوان بازی کرد. زمانی که Outlookدر حالتSunny باید دیگر شرایط بررسی شود. بنابراین ویژگی بعد در جدول بر اساس یک سری پارامترها انتخاب شده و ریشه بعدی را Humidity را انتخاب کرده که در مقادیر ستونهای Humidity، مقدار High و Normal رو داریم در حالتی که Humidity ، Normal باشد شرایط برای بازی مساعد است و زمانی که Humidity، High باشد شرایط برای بازی مساعد نیست.
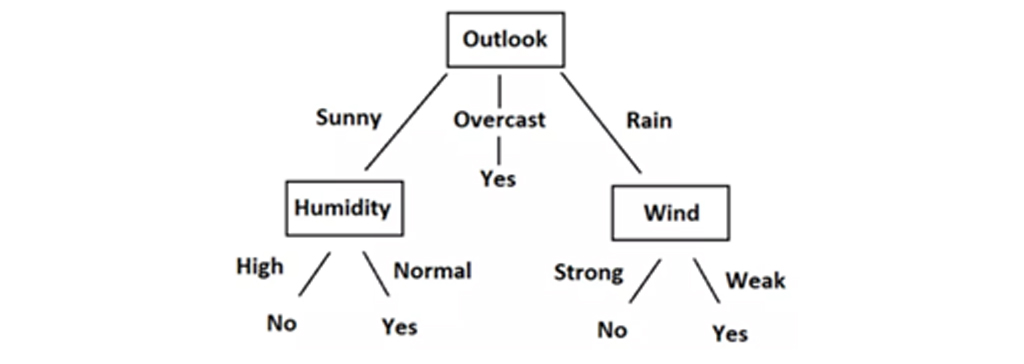
با مشاهده Data ، Rules و Tree متوجه شدیم که چگونه میتوانیم پیشبینی کنیم که آیا باید تنیس بازی کنیم یا نه ، با توجه به شرایط آب و هوایی براساس ویژگیهای مستقل این تصمیمگیری انجام میشود. کل این فرایند ایجاد قوانین بر اساس داده های داده شده چیزی نیست جز آموزش مدل درخت تصمیم. ما میتوانیم با مشاهده، تنها یک قانون ایجاد کنیم و یک درخت درست کنیم زیرا مجموعه داده بسیار کوچک است. اما اینکه چگونه درخت تصمیم روی مجموعه داده های بزرگتر آموزش داده میشود برای آن، باید کمی ریاضیات را بدانیم.
مفاهیم ریاضی درخت تصمیم
مفاهیم ریاضی پشت درخت تصمیم از دو مفهوم مهم تشکیل شده است: Entropy و Gain information. آنتروپی، اندازه گیری تصادفی بودن یک سیستم است. در اینجا 14 ردیف در جدول داده داریم بنابراین 14 عضو برای اندازه گیری انتروپی خواهیم داشت.
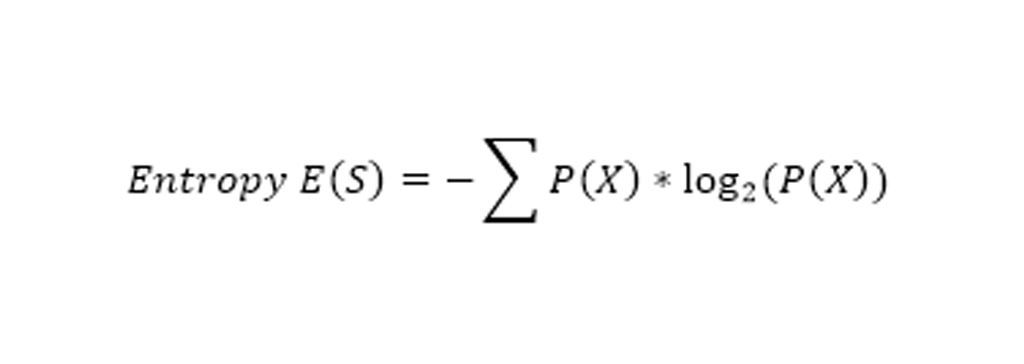
آنتروپی سیستم با فرمول فوق محاسبه می شود که احتمال گرفتن کلاس از آن 14 عضو است. ما در اینجا دو کلاس داریم که یکی Yes و دیگری No در ستون Play است. ما در مجموعه داده های خود 9 بله و 5 نه داریم. به عبارتی 9/14 احتمال بازی کردن و 5/14 احتمال بازی نکردن، بنابراین محاسبه آنتروپی در اینجا به شرح زیر خواهد بود.
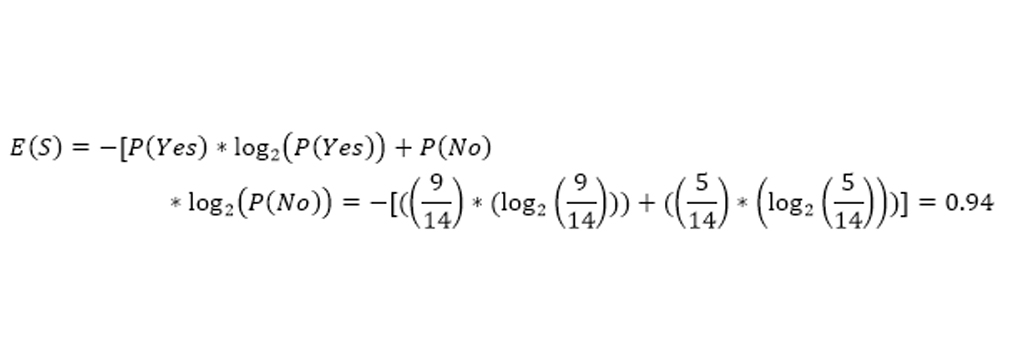
Gain information به دست آوردن اطلاعات، مقداری است که به دلیل انشعابی که انجام شده، آنتروپی سیستم کاهش مییابد و این با استفاده از مشاهدات ایجاد شده است. اما اینکه چطور که ابتدا داده ها را بر اساس Outlook و نه بر اساس ویژگی دیگری تقسیم شد به دلیل این امر این است که این تقسیم باعث کاهش حداکثر آنتروپی میشود اما در مثال فوق بصورت شهودی آن را انجام شد.
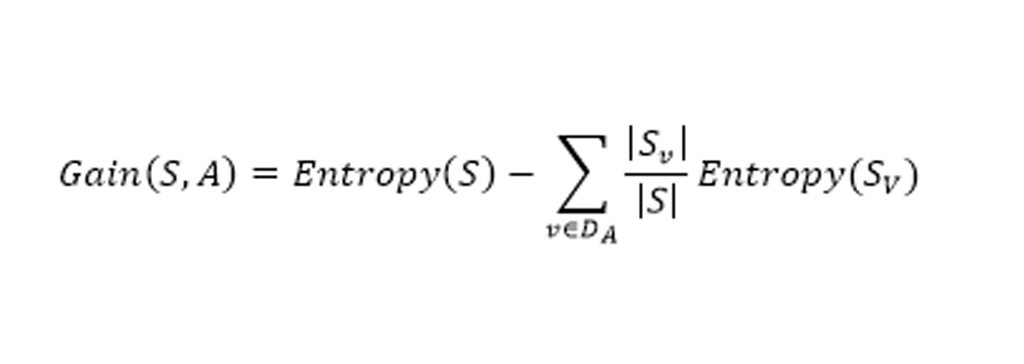
مقادیر E در هر تقسیم مقادیر آنتروپی را نشان میدهد که خود را به عنوان یک سیستم کامل در نظر میگیرند و از فرمول آنتروپی بالا استفاده میکنند.میزان کسب اطلاعات برای هر ویژگی را به طور مستقل محاسبه میشود. و نتایج زیر را بدست می آوریم:
- Gain (S, Outlook) =0.247
- Gain (S, Humidity) =0.151
- Gain (S, Wind) =0.048
- Gain (S, Temperature) =0.029
میتوان دید که با تقسیم بر ویژگی هدف، حداکثر اطلاعات را به دست میآوریم. باتکرار این روش تا ایجاد درخت کامل پیش میرویم. این روال برای ایجاد هر درخت به صورت کامل ادامه مییابد و سپس با توجه به نتایج هر درخت رای گیری انجام میشود و مقداری که با اکثریت ارا باشد به عنوان نتیجه ی نهایی انتخاب میشود.
مثال الگوریتم جنگل تصادفی Random Forest
نحوه کار الگوریتم را می توان با مثال الگوریتم جنگل تصادفی Random Forest بهتر درک کرد:
مثال: فرض کنید مجموعه داده ای وجود دارد که شامل چندین عکس میوه است. بنابراین ، این مجموعه داده به طبقه بند Random forest داده میشود. مجموعه داده به زیرمجموعه ها تقسیم شده و به هر درخت تصمیم داده میشود. در طول مرحله آموزش، هر درخت تصمیم یک نتیجه پیشبینی تولید میکند، و هنگامی که یک نقطه داده جدید رخ میدهد، سپس بر اساس اکثر نتایج، طبقه بندی جنگل تصادفی تصمیم نهایی را پیشبینی میکند. تصویر زیر را در نظر بگیرید:
کاربرد الگوریتم جنگل تصادفی Random Forest
برنامه های جنگل تصادفی به طور عمده چهار بخش مانند بانکداری، بازار بورس، پزشکی و تجارت الکترونیک بسیار مورد استفاده قرار گرفته است که تعدادی از این موارد کاربرد الگوریتم جنگل تصادفی Random Forest به شرح زیر میباشد:
بانکداری: در بانکداری، بیشتر از این الگوریتم برای شناسایی ریسک وام استفاده میکند و همچنین برای شناسایی مشتریانی که بیشتر از سایرین از خدمات بانکی استفاده میکنند و بدهی خود را به موقع باز میگردانند استفاده میشود. این الگوریتم برای شناسایی مشتریان کلاهبرداری که قصد کلاهبرداری از بانک را دارند نیز مورد بهرهبرداری قرار میگیرد.
پزشکی: در حوزه پزشکی، این الگوریتم برای شناسایی ترکیب صحیحی از مولفهها و تحلیل تاریخچه پزشکی بیمار، برای شناسایی بیماری او مورد استفاده قرار میگیرد. با کمک این الگوریتم میتوان روند بیماری و خطرات بیماری را شناسایی کرد.
بازاریابی: روندهای بازاریابی را میتوان با استفاده از این الگوریتم شناسایی کرد. در تجارت الکترونیک (E-commerce)، جنگل تصادفی برای شناسایی اینکه مشتریان یک محصول را دوست داشتهاند یا خیر، استفاده میشود.
تجارت الکترونیک: در امور مالی، از جنگل تصادفی برای شناسایی رفتار بورس در آینده استفاده میشود و میتوان از این نوع الگوریتمها برای ایجاد سیستمهای مشاوره در زمینهی بورس استفاده کرد.
مزایا الگوریتم جنگل تصادفی Random Forest
یکی از بزرگترین مزایا جنگل تصادفی Random Forest تطبیق پذیری آن است. هم برای کارهای رگرسیون و هم برای طبقه بندی قابل استفاده است و همچنین مشاهده اهمیت نسبی که به ویژگیهای ورودی اختصاص میدهد. جنگل تصادفی نیز یک الگوریتم بسیار مفید است زیرا ابر پارامترهای پیش فرضی که از مشاهدات و ویژگیها استفاده میکند، اغلب نتیجه پیش بینی خوبی ایجاد میکند.
درک بیش از حد پارامترها کاملاً ساده است. این الگوریتم بسیار انعطافپذیر است زیرا جنگل تصادفی میتواند وظایف رگرسیون و طبقه بندی را با درجه دقت بالایی کنترل کند و به این دلیل یک روش محبوب در بین دانشمندان داده است. دسته بندی کردن ویژگی در طبقه بنده جنگل تصادفی را به ابزاری موثر برای تخمین مقادیر از دست رفته تبدیل میکند زیرا در هنگام از دست دادن بخشی از داده ها دقت را حفظ میکند.
معایب الگوریتم جنگل تصادفی Random Forest
از جمله معایب الگوریتم جنگل تصادفی Random Forest میتوان به وقت گیر بودن این فرآیند اشاره کرد، از آنجا که الگوریتم های تصادفی جنگل میتوانند مجموعه داده های بزرگی را کنترل کنند، میتوانند پیشبینی های دقیقتری را ارائه دهند، اما پردازش داده ها به دلیل محاسبه داده ها برای هر درخت تصمیم خاص، کند است.
از دیگر معایب این الگوریتم این است که به منابع بیشتری نیاز دارد، از آنجا که جنگلهای تصادفی مجموعه داده های بزرگتری را پردازش میکنند، برای ذخیره داده های مورد پردازش به منابع بیشتری نیاز دارند. یکی از بزرگترین مشکلات در یادگیری ماشین، مشکل Overfitting است، اما بیشتر اوقات این امر به لطف طبقه بندی کننده تصادفی جنگل اتفاق نخواهد افتاد. اگر به اندازه کافی درخت در جنگل وجود داشته باشد، برای طبقه بندی کننده مشکل Overfitting وجود نخواهد داشت.
جمع بندی الگوریتم جنگل تصادفی Random Forest
الگوریتم جنگل تصادفی Random Forest ترکیبی از درختان تصمیم گیری است که میتواند برای پیشبینی و تجزیه و تحلیل رفتار مدل شود. تکنیک جنگل تصادفی به دلیل قابلیت کار با بسیاری از متغیرها که هزاران داده را در اختیار دارد، میتواند مجموعه داده های بزرگی را کنترل کند. همانطور که مشاهده میکنید، مجموعهای از درختهای تصمیم وجود دارند که به هر کدام از آنها یک زیر مجموعهای از دادهها تزریق میشود.
هر کدام از الگوریتمها عملیاتِ یادگیری را انجام میدهند. در هنگام پیشبینی، یعنی وقتی که یک سری دادهی جدید به الگوریتم، جهت پیشبینی داده میشود، هر کدام از این الگوریتمهای یادگرفته شده، یک نتیجه را پیشبینی میکنند. الگوریتمِ جنگلِ تصادفی در نهایت، میتواند با استفاده از رایگیری، آن طبقهای را که بیشترین رای را آورده است انتخاب کرده و به عنوانِ طبقهی نهایی جهت انجامِ عملیات طبقهبندی قرار دهد.
نویسنده: تیم پژوهش راهبرد
منابع
analyticsvidhya.com
LEO BREIMAN,” Random Forests”, Machine Learning, 45, 5–32, 2001

دیدگاهتان را بنویسید