خوشه بندی در داده کاوی
سرفصل مطالب
خوشه بندی در داده کاوی
خوشه بندی در داده کاوی Clustering : یکی از روشهای کاوش در داده های انبوه و کشف اطلاعات و دانش از این داده ها، داده کاوی میباشد. برای استخراج الگو از این داده ها الگوریتم های متعددی مورد استفاده قرار میگیرند و هرکدام موارد استفاده مخصوص به خود را دارند. یکی از مهمترین و پرکاربرد ترین تکنیکهای داده کاوی استفاده از الگوریتم های خوشه بندی است. خوشه بندی یا دسته بندی داده ها با استفاده از شباهت های ذاتی آنها داده های مشابه را در یک گروه قرار میدهد. و بر اساس این دسته بندی و شباهت به کشف الگو و استخراج نهفته در ذات داده ها میپردازد. و یافتن این الگوها مدیریت داده ها برای کاربردهای مختلف بسیار آسان میکند.
روش طبقه بندی در داده کاوی را که یک روش یادگیری با نظارت است را نیز در این خصوص مطالعه فرمایید.
خوشه بندی یا دسته بندی داده ها
خوشه بندی یا دسته بندی داده ها : خوشه بندی یک روش یادگیری بدون نظارت است. یک روش یادگیری بدون نظارت روشی است که در آن دیتاست مورد نظر حاوی داده هایی است بدون برچسب هدف یا گروهی که داده به آن متعلق است. به طور کلی، از آن به عنوان فرایندی برای یافتن ساختار یا الگویی معنی دار برای دسته بندی داده ها بکار میرود.
خوشه بندی وظیفه تقسیم جمعیت یا نقاط داده به تعدادی گروه است به گونه ای كه نقاط داده در گروهی که عضو است بیشترین شباهت را به سایر نقاط داده در همان گروه داشته باشد و با نقاط داده در گروههای دیگر شباهتی نداشته باشد. در اصل مجموعه ای از اشیا یا داده ها بر اساس شباهت و عدم شباهت تقسیم بندی میشوند؛ این یک وظیفه اصلی برای کاوش داده و یک روش برای تجزیه و تحلیل داده های کلان است که در بسیاری از زمینه ها از جمله شناخت الگو، تجزیه و تحلیل تصویر، بازیابی اطلاعات، بیوانفورماتیک، فشرده سازی داده ها، گرافیک رایانه و یادگیری ماشین مورد استفاده قرار میگیرد.
الگوریتم های خوشه بندی داده هایی را که ویژگیهای مشابه به هم و نزدیک دارند را در دستههای جداگانه که به آن خوشه گفته میشود قرار میدهند. با نگاهی ساده تر به مسئله خوشه بندی در میابیم که خوشه بندی میتواند همان دسته بندی باشد که روزانه بارها بدون توجه به اینکه این عمل را انجام میدهیم از آن برای دستهبندی وسایل استفاده میکنیم. زمانیکه با تعدادی اشیاء با صفات مختلف ولی محدود رو به رو هستیم به راحتی اشیاء را دسته بندی میکنیم.
به طور مثال کودکی تعدادی تیله دارد و تیله ها را روی زمین میریزد. با نگاهی به تیله ها متوجه میشود تعدادی تیله آبی رنگ، تعدادی زرد و تعدادی قرمز رنگ است به راحتی آنها را از روی رنگ در سه دسته قرار میدهد. زمانی که دقیقتر نگاه میکند تعدادی تیله بزرگتر و تعدادی کوچکتر است باز هم میتواند تیله ها را به دلخواه بر اساس سایز دسته بندی کند. و زمانی که مجدد به تیله های دسته بندی شده با دقت بیشتری نگاه میکند متوجه ترک و ساییدگی روی بعضی از تیله ها میشود و اگر بخواهد همه ی این ویژگیها اعم از سایز تیله ها، رنگ، و سالم بودن را در دسته بندی خود دخیل کند کار مشکل میشود و دچار سردرگمی میگردد. و به احتمال زیاد دسته بندی را رها کرده و به بازی مشغول میشود!

هنگامی که با یک مجموعه کوچک و با ویژگیهای محدودی از این مجموعه رو به رو هستیم، دسته بندی این مجموعه کاری اسان است و به راحتی میتوانیم آن را انجام دهیم. اکنون فرض کنید در یک مجموعه متشکل از هزاران داده و با تعداد زیادی ویژگی رو به رو هستید و قصد دسته بندی این داده ها را دارید؛ این کار برای انسان بسیار سخت و طاقت فرسا است. این جاست که کار دسته بندی با تعداد ویژگی های زیاد از صبر و حوصله ی انسان خارج میشود و الگوریتم های خوشه بندی بهترین ابزار برای حل این گونه مشکلات است، از این الگوریتمها در مجموعه دادههای بزرگ و در مواردی که تعداد ویژگیهای داده زیاد باشد استفاده میشود.
عمل تجزیه و تحلیلی که توسط الگوریتم های خوشه بندی انجام میشود تفاوت زیادی با دسته بندی داده توسط انسان دارد چون این الگوریتمها درک دقیقی از داده ها و تشکیل یک خوشه و چگونگی یافتن کارآمد یک خوشه دارند.
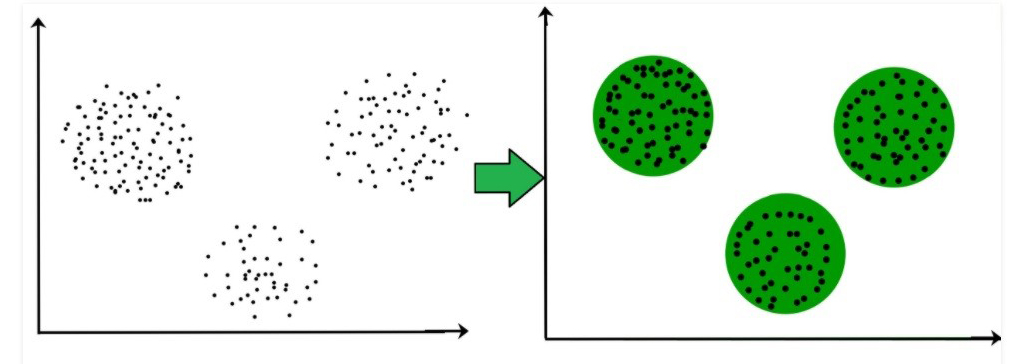
ویژگیهایی که این الگوریتمها بر اساس آن، این خوشه ها را ایجاد میکنند شامل خوشه هایی با فاصله کم بین اعضای خوشه، خوشه هایی با تراکم بالای داده، فاصله ها و توزیع های اماری خاص است. نقاط داده را در نمودار زیر که بصورت خوشه ای در کنار هم جمع شده اند را میتوان به عنوان یک خوشه در نظر گرفت. میتوان خوشه ها را از هم تفکیک کرد و همچنین میتوان تشخیص داد که در تصویر زیر 3 خوشه وجود دارد.
انواع روشهای خوشه بندی در داده کاوی
اگر چه بیشتر الگوریتمها یا روشهای خوشهبندی مبنای یکسانی دارند ولی تفاوتهایی در شیوه اندازهگیری شباهت یا فاصله و همچنین انتخاب برچسب برای اشیاء هر خوشه در این روشها وجود دارد.
1-روش های مبتنی بر تراکم (Density-Based Methods):
خوشهها در مناطقی با چگالی بیشتر هستند (نقاط داده متراکمتر) که با نواحی دارای چگالی کمتر (تراکم داده کم) از هم جدا شدهاند. در این روشها، نقاطی که در یک محدوده معین (یک شعاع همسایگی خاص) از هم قرار دارند در یک خوشه قرار میگیرند. در روشهای مبتنی بر چگالی، معمولا یک حداقل چگالی در نظر گرفته میشود و در نواحی که این حداقل رعایت شده، خوشهبندی انجام میشود. این روشها ذاتا برای فضای پیوسته تعریف شدهاند. در شکل زیر تعدادی داده داریم در هر منطقهای که تراکم دادهها بیشتر است دادهها تشکیل یک خوشه داده اند.
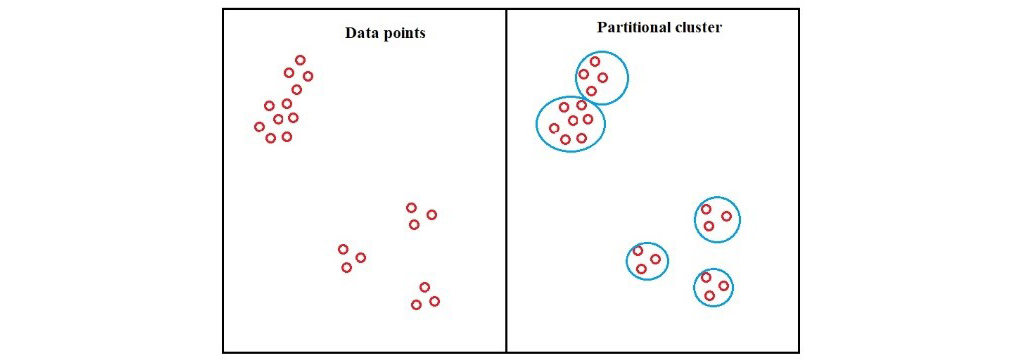
2-روشهای پارتیشن بندی (Partition methods):
روشهای پارتیشن بندی بدین شرح است که یک زیرمجموعه از مجموعه دادههای مورد نظر را به تعداد K تا مجموعه از پیش تعیین شده از زیرمجموعه های دارای داده تقسیم میکنیم. آنها برای بدست آوردن گروههایی با یک شکل کروی یا حداکثر محدب مناسب هستند و می توانند در مجموعه داده هایی با اندازه ی کوچک یا متوسط استفاده شوند. در این روش، براساس n مشاهده و k گروه، عملیات خوشهبندی انجام میشود. به این ترتیب تعداد خوشهها یا گروهها از قبل در این الگوریتم مشخص است. با طی مراحل خوشهبندی تفکیکی، هر شیء فقط و فقط به یک خوشه تعلق خواهد داشت و هیچ خوشهای بدون عضو باقی نمیماند. از انواع روشهای پارتیشنبندی میتوان به k-means ,k-median ,Fuzzy C-means اشاره کرد.
خوشه بندی k-means
خوشه بندی k-means : الگوریتم k-means یکی از سادهترین و محبوبترین الگوریتمهای خوشه بندی است که در دادهکاوی بخصوص در حوزه ی یادگیری نظارت نشده به کار میرود. معمولا در حالت چند متغیره، باید از ویژگیهای مختلف اشیا به منظور طبقهبندی و خوشه کردن آنها استفاده کرد. به این ترتیب با دادههای چند بعدی سروکار داریم که معمولا به هر بعد از آن، ویژگی یا خصوصیت گفته میشود. با توجه به این موضوع، استفاده از توابع فاصله مختلف در این جا مطرح میشود. ممکن است بعضی از ویژگیهای اشیا کمی و بعضی دیگر کیفی باشند.
3-روشهای سلسله مراتبی (Hierarchical methods):
روشهای سلسله مراتبی، روش درختی داده ها را به زیر گروه هایی تقسیم میکند در این الگوریتمها نیازی به تعیین تعداد زیر گروه ها نیست. انواع روشهای سلسله مراتبی شامل روش تقسیمی (Divisive hierarchical methods) و روش تجمعی ( Agglomerative hierarchical methods) است. روش تقسیمی یک روش خوشه بندی از بالا به پایین است و از کل داده شروع میشود و در نهایت به کوچکترین جزء میرسد. و روش تجمعی دقیقا عکس روش تقسیمی است و یک روش پایین به بالا است از کوچکترین جزء شروع میکند و در نهایت تمامی دادهها در یک دسته قرار میگیرند.
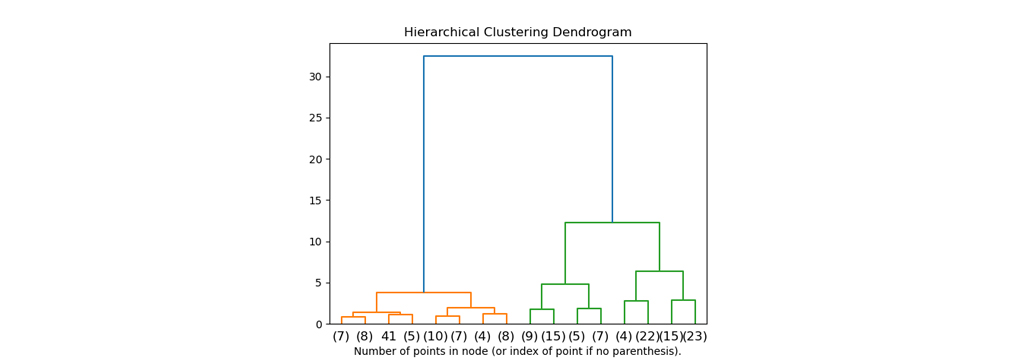
خوشه بندی isodata (ایزودیتا (آیسودیتا)):
الگوریتم isodata (ایزودیتا (آیسودیتا)) یک روش خوشه بندی سلسله مراتبی است که با استفاده از تراکم دادهها، گروههای مختلف را تشکیل میدهد. این روش بر اساس فاصله بین نقاط داده و نقاط تراکم آنها، گروهبندی میکند. این روش در زمینههایی مانند تجزیه و تحلیل تصویر، شبکهسازی و شناسایی الگو استفاده میشود. جهت مطالعه بیشتر در مورد الگوریتم isodata (ایزودیتا (آیسودیتا)) کلیک کنید.
4- روشهای شبکه ای (Grid methods):
روش شبکه ای، دسته خاصی از روشهای مبتنی بر چگالی هستند که در آنها هر منطقه مجزا در فضای داده که جستوجو میشود، در ساختار شبکه مانندی قرار میگیرد. به طور مثال نقاط داده شده در صفحه مختصات رسم شده و سپس صفحه به شبکه هایی تقسیم میشود و نقاطی که با هم در یک شبکه قرار بگیرند در یک خوشه قرار دارند این روش به نسبت دیگر روشها درصد صحت پایین تری دارد ولی زمان بسیار مناسبی در خوشه بندی دارد.
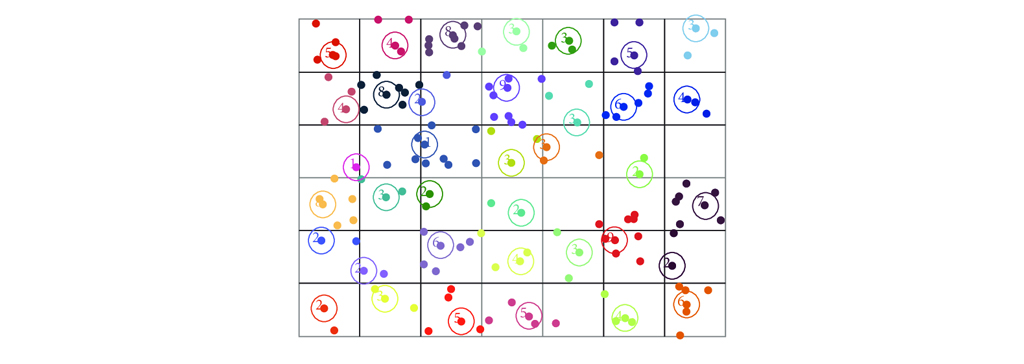
کاربردهای خوشه بندی در داده کاوی
از کاربرد خوشه بندی می توان به موارد زیر اشاره کرد:
- بازاریابی: خوشه بندی میتواند در زمینه های مختلف بازاریابی کاربرد داشته باشد به طور مثال از خوشه بندی برای توصیف و کشف رفتار مشتری، توانایی خرید مشتری و برای انجام تبلیغات بهینه از اهداف بازاریابی میتوان استفاده کرد.
- زیست شناسی: یکی دیگر از توانایی های خوشه بندی این است که آن را برای طبقه بندی در میان گونه های مختلف گیاهان و حیوانات استفاده کرد و این خود به زیست شناسان بسیار کمک میکند.
- کتابخانه ها: در خوشه بندی کتاب های مختلف بر اساس موضوعات و اطلاعات استفاده می شود و بسیار کار جست و جوی کتاب را راحت تر کرده است.
- بیمه: برای تأیید مشتریان ، بیمه نامه های آنها و شناسایی کلاهبرداری ها به کار می رود.
- برنامه ریزی شهری: برای ساختن گروه هایی از اطلاعات خانه ها و بررسی ارزش های آنها بر اساس موقعیت جغرافیایی و سایر عوامل موجود استفاده میشود و از این گروه ها برای قیمت گذاری استفاده میشود تا نظر اشخاص در تعیین قیمت کمتر تاثیرگذار باشد.
- مطالعات زلزله: با بررسی مناطق زلزله زده و بررسی وضعیت صفحات زمین میتوان مناطق خطرناک را تعیین کرد.
- تقسیم بندی بازار: بخش بندي بازار، هدف گيري شرکت ها را به سمت بازارهاي مشخص تري هدايت مي کنند تا ارتباط موثرتري با مشتريان صورت پذيرد. که بدین وسیله بتوانند زمينه تصميم گيري سريع و منطبق با واقعيت را فراهم کند.
- تحلیل شبکه اجتماعی: تشخیص انجمنها و خوشه بندی گراف در یک شبکه اجتماعی به ساده سازی و تحلیل بهتر آن کمک میکند. انجمنها گروه هایی از نودهای شبکه هستند که ارتباط تنگاتنگی با هم دارند و با نودهای بیرون از شبکه ارتباط نسبتا کمی دارند. بعنوان مثال اگر ارتباطات اجتماعی افراد را در یک شبکه اجتماعی داشته باشیم دوستان هم کلاس در یک دانشکده از یک دانشگاه ممکن است تشکیل یک گروه با ارتباطات تنگاتنگ بدهند و در حقیقت یک انجمن در این شبکه اجتماعی باشند.
- گروه بندی نتایج جستجو: گروه بندی و به نظم درآوردن نتايج جستجو در بازيابي اطلاعات، بخصوص وقتي حجم منابع پیشنهاد شده بسيار زياد است به كاربران در بدست آوردن اطلاعات مورد نظر کمک میکند. بازآرايي و سازماندهي مدارك همواره بر اساس ويژگي هاي هر مدرك صورت ميپذيرد.
- تصویربرداری پزشکی و پزشکی: در تصویربرداری PET تجزیهی خوشهای میتواند برای تمایز بین انواع مختلف بافت در یک تصویر سه بعدی برای بسیاری از اهداف مختلف مورد استفاده قرار گیرد. کاربرد خوشهبندی در پزشکی میتواند برای تجزیه و تحلیل الگوهای مقاومتی آنتیبیوتیکی، طبقهبندی ترکیبات ضد میکروبی مطابق با مکانیسم عمل آنها، طبقهبندی آنتیبیوتیکها بر اساس فعالیت ضد باکتری آنها استفاده شود.
- سیستم توصیه گر: سیستمهای توصیه شده به منظور توصیف ایتم جدید بر اساس سلیقه کاربر طراحی شدهاند. با استفاده از الگوریتم های خوشه بندی میتوان سیستم های پیشنهاد دهنده ای طراحی کرد که بر اساس سلیقه و ذائقه مخاطب به او کالای مورد نیاز، فیلم و یا موزیک و غیره پیشنهاد دهند. بر اساس جست و جوهای قبلی یا برای پیشبینی ترجیحات کاربر بر اساس ترجیحات دیگر کاربران در خوشه کاربر استفاده میکنند.
- در زمینه رباتیک الگوریتم خوشه بندی برای آگاهی موقعیت رباتیک برای ردیابی اشیاء و تشخیص خروجیها در دادههای سنسور استفاده میشود.
- بخش بندی تصویر: خوشه بندی میتواند برای تقسیم یک تصویر دیجیتال به مناطق مشخص برای تشخیص مرز یا تشخیص شی مورد استفاده قرار گیرد.
اهمیت خوشه بندی در هوش تجاری
در تحقیقات بازار استفاده از تجزیه و تحلیل به روش خوشه بندی میتواند به طور گسترده کاربرد داشته باشد؛ کارشناسان و محققان در زمینه ی پژوهش های بازار از الگوریتم های خوشه بندی استفاده میکنند. به طور مثال در تحقیقات حوزه بازاریابی برای تقسیم بندی مخاطبانِ تبلیغات مختلف و همچنین در دسته بندی نتایج نظرسنجی کاربرد فراوان دارد.
بدین وسیله محققان، مشتریان و مصرف کنندگان بخشهای مختلف بازار را به گروه هایی مشخص تقسیم کنند تا روابط بین گروه های مختلف مصرف کنندگان بالقوه، گروه بندی اقلام خریداری شده توسط مشتری، برای دسته بندی اقلام موجود در فروشگاههای اینترنتی استفاده میشود.
به عنوان مثال، تمام اقلام مشابه موجود در یک فروشگاه اینترنتی را میتوان با استفاده از روشهای خوشه بندی در یک گروه قرار داد و با استفاده از این خوشه بندی مشتری راحت تر کالای مورد نیاز خود را جست و جو کند و همچنین با پیگیری خرید مشتری میتوان پیشنهادهایی نزدیک به سلیقه مشتری به او داد و این خود باعث تشویق خرید از محصولات مورد نظر میشود و همچنین مصرف کننده احساس میکند از طرف سیستم به خوبی نیازها و سلیقه ی او درک شده است و این امر موجب تبدیل شدن مشتری معمولی به یک مشتری وفادار میشود . با استفاده از دسته بندی فرمهای نظرسنجی بخصوص فرمهای انلاین میتوان نظرات مصرف کنندگان و مخاطبان را دسته بندی کرد و به راحتی میزان رضایت و نارضایتی و همچنین دلایل رضایت و نارضایتی را بدست آورد و در راستای افزایش رضایت مصرف کننده تلاش کرد. بنابراین الگوریتم های داده کاوی جزء جدایی ناپذیر تجزیه و تحلیل داده ها در حوزه ی کسب و کار است.
جمع بندی خوشه بندی در داده کاوی
خوشه بندی در داده کاوی یکی از مهم ترین الگوریتم های یادگیری بدون ناظر در داده کاوی است. ما با داده های بسیاری در حوزه های مختلف سر و کار داریم که بسیاری از این داده ها نیاز به دسته بندی دارند. تعدادی از این داده ها، بدون برچسب هستند یعنی گروهی که این دادهها به آن تعلق دارند برخلاف الگوریتمهای یادگیری با ناظر مشخص نیست. بنابراین ما برای تجزیه و تحلیل این داده ها نیاز به روشهای خوشه بندی داریم و به طور کلی خوشه بندی، گروهبندی ذاتی را در بین داده های بدون برچسب تعیین میکند؛ و این گروه بندی ذاتی داده ها در رفع مسائل کنونی برای یافتن الگو در این حجم وسیع داده بسیار میتواند در همه ی زمینه ها مفید باشد.
نویسنده: تیم پژوهش راهبرد

دیدگاهتان را بنویسید