الگوریتم Knn یا الگوریتم K نزدیکترین همسایه
سرفصل مطالب
الگوریتم Knn یا الگوریتم K نزدیکترین همسایه ( K-Nearest Neighbors )
یادگیری ماشین یکی از پرکاربرد ترین زمینه های هوش مصنوعی در عصر اطلاعات است. افراد فعال در این حوزه همیشه سعی بر این دارند که الگوریتم هایی با کارایی بالا و توانمند برای آموزش سیستم های یادگیر طراحی کنند و گاهاً می بینیم الگوریتم های قدیمی در این زمینه به خوبی جواب می دهند. الگوریتم Knn یا الگوریتم K نزدیکترین همسایه ( K-Nearest Neighbors ) یکی از این الگوریتم های توانمند است. الگوریتم K نزدیکترین همسایه (KNN) یک الگوریتم یادگیری ماشین نظارت شده است و از ویژگی های آن سادگی و آسانی این الگوریتم برای پیاده سازی است که می تواند برای حل مسائل طبقه بندی و رگرسیون مورد استفاده قرار گیرد. الگوریتم نزدیک ترین همسایگی کاربرد فراوانی در داده کاوی دارد و یک الگوریتم بسیار محبوب در این زمینه است.
الگوریتم یادگیری ماشین با نظارت
یک الگوریتم یادگیری ماشین با نظارت (بر خلاف الگوریتم یادگیری ماشین بدون نظارت) الگوریتمی است که بر داده های ورودی دارای برچسب متکی است تا عملکردی را یاد بگیرد که هنگام ورود داده های بدون برچسب جدید خروجی مناسب تولید می کند. تصور کنید کامپیوتر یک کودک است، ما سرپرست آن هستیم و ما می خواهیم کودک (رایانه) یاد بگیرد که یک مربع چیست. ما چندین تصویر مختلف را به کودک نشان می دهیم که برخی از آن ها مربع هستند و بقیه می توانند تصاویر هر چیزی (دایره ، مثلث و غیره) باشند. وقتی مربع را می بینیم اسم مربع را می گوییم و زمانی که شکل دیگری را می بینیم می گوییم نه مربع نیست. پس از چندین بار انجام این کار با کودک، ما یک عکس به او نشان می دهیم و می پرسیم “مربع؟” و کودکان معمولاً به درستی در (بیشتر اوقات) می گویند “مربع!”.

یادگیری سیستم های کامپیوتری مانند آموزش دادن به کودک است. ابتدا باید تعدادی نمونه به سیستم یادگیر نشان دهیم تا سیستم بر اساس الگوهای استخراجی بتواند نمونه های جدید را به درستی یاد بگیرد. زمانی که ما نمونه را به سیستم یادگیر می دهیم و برچسب آن را هم تعیین می کنیم به این نوع یادگیری، یادگیری با نظارت گفته می شود. الگوریتم های یادگیری ماشین تحت نظارت برای حل مسائل طبقه بندی یا رگرسیون استفاده می شود.
الگوریتم K Nearest Neighbor
الگوریتم K Nearest Neighbor در گروه یادگیری تحت نظارت قرار می گیرد و برای طبقه بندی (رایج ترین) و رگرسیون استفاده می شود. این یک الگوریتم همه کاره است همچنین برای محاسبه مقادیر از دست رفته و نمونه گیری مجدد مجموعه داده ها استفاده می شود. همانطور که از نام (K Nearest Neighbor) پیداست، K نزدیکترین همسایه ها (نقاط داده) را برای پیش بینی کلاس یا مقدار پیوسته برای Datapoint (داده جدید) جدید در نظر می گیرد.
یادگیری یک الگوریتم عبارت است از:
- 1. Instance-based learning(یادگیری مبتنی بر نمونه): در اینجا ما برای پیش بینی خروجی (مانند الگوریتم های مبتنی بر مدل) وزن داده های آموزش(ارزش داده ها) را نمی آموزیم بلکه از کل موارد آموزشی برای پیش بینی خروجی برای داده های جدید استفاده می کنیم.
- Lazy Learning (یادگیری تنبل): مدل از قبل توسط داده های آموزشی فرآیند یادگیری را انجام نمی دهد و فرآیند یادگیری به زمانی موکول می شود که پیش بینی در مورد نمونه جدید درخواست می شود.
- Non -Parametric: (بدون پارامتر): در KNN، هیچ شکل از پیش تعیین برای طبقه بندی وجود ندارد.
چه زمانی از الگوریتم KNN یا K-Nearest Neighbors استفاده می کنیم؟
چه زمانی از الگوریتم KNN یا K-Nearest Neighbors استفاده می کنیم؟ KNN را می توان هم برای طبقه بندی و هم برای مسائل پیش بینی رگرسیون استفاده کرد. با این حال، بیشتر در مسائل طبقه بندی در صنعت استفاده می شود. برای ارزیابی هر تکنیک یادگیری ماشین به طور کلی به 3 جنبه مهم توجه می کنیم:
- سهولت در تفسیر خروجی
- زمان محاسبه
- قدرت پیش بینی
در ادامه به بررسی یک مورد ساده برای درک این الگوریتم بررسی می کنیم. در زیر محل دایره های قرمز (RC) و مربع های سبز (GS) آمده است:
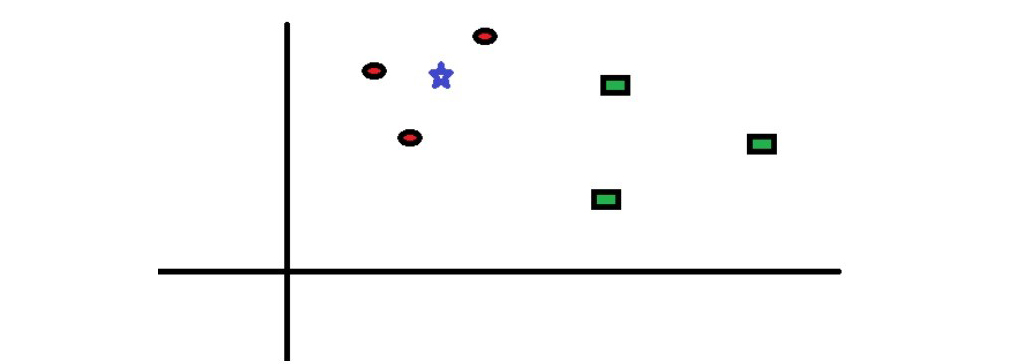
می خواهیم کلاس ستاره آبی (BS) را بیابیم. BS می تواند در گروه RC یا GS قرار بگیرد. الگوریتم KNN ، “K” تا از نزدیکترین همسایه ای است که می خواهیم بررسی کنیم را در نظر می گیریم. برای شروع کار K=3 در نظر می گیریم. بنابراین، اکنون یک دایره با مرکز BS در نظر می گیریم. درست به اندازه ای این دایره را بزرگ می کنیم که فقط سه نقطه داده را در صفحه قرار می دهد به دلیل همان K=3 . برای جزئیات بیشتر به نمودار زیر مراجعه کنید:
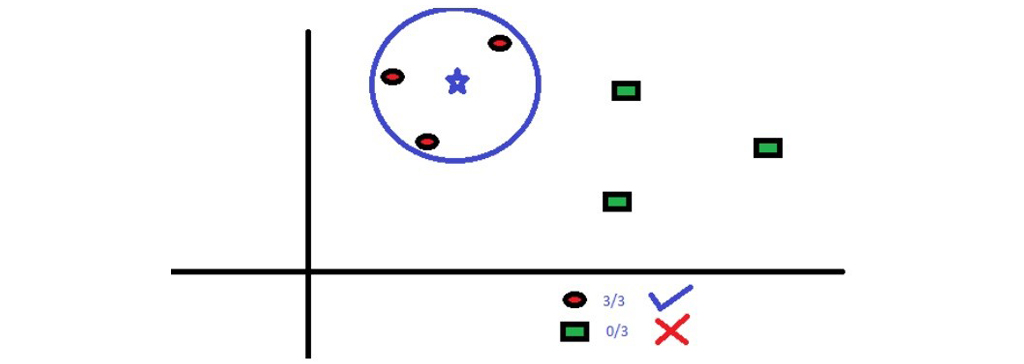
سه نقطه نزدیک به BS همه جزو RC است. بنابراین، با یک سطح اطمینان خوب، می توان گفت که BS باید متعلق به کلاس RC باشد. در اینجا، انتخاب بسیار ساده شد زیرا هر سه رای نزدیکترین همسایه به RC منتهی شد. انتخاب پارامتر K در این الگوریتم بسیار مهم است. در قسمت بعد این مطلب به بررسی چگونگی انتخاب K می پردازیم، بررسی می کنیم که چه عواملی را باید در نظر گرفت تا بهترین K را الگوریتم هر چه زودتر انتخاب کند.
چگونه فاکتور K را انتخاب می کنیم؟
چگونه فاکتور K را انتخاب می کنیم؟ در ابتدا بررسی می کنیم که پارامتر K دقیقاً روی چه مواردی در الگوریتم اثر می گذارد. در مثال تشخیص کلاس سناره آبی ما 6 نمونه آموزشی داشتیم، با تعیین K درست توانستیم مرز بین RC و GS را حدس بزنیم و به درستی مرز را تعیین بکنیم. به همین ترتیب، بیایید تلاش کنیم تأثیر مقدار “” K را در مرزهای کلاس ببینیم. در زیر مرزهای مختلف جدا کننده دو کلاس با مقادیر مختلف K آمده است. میزان K ای درست است که بتواند مرزی را تعیین کند که با کمترین خطا داده های قرمز و آبی از یک دیگر جدا شوند.
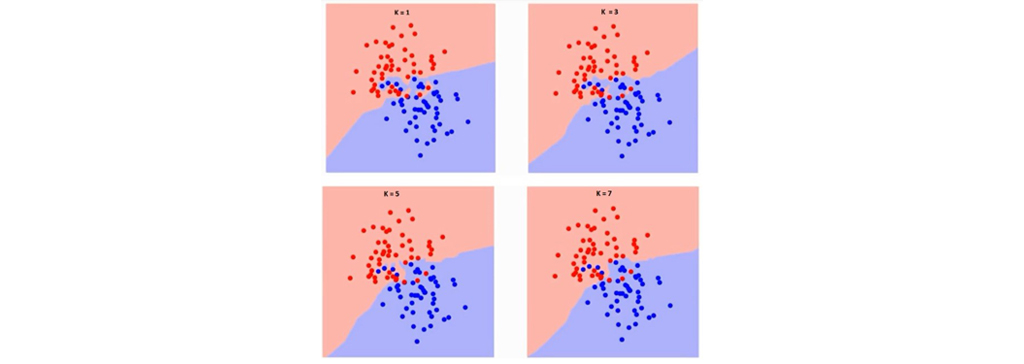
اگر با دقت تصاویر بالا را بررسی کنید، می بینید که با افزایش مقدار K مرز بین دو کلاس هموارتر می شود. برای تعیین میزان درست K باید دو پارامتر خطای آموزش و خطای اعتبار سنجی را بررسی کنیم. میزان خطای آموزش به مقداری گفته می شود که در سیستم بعد از اینکه با داده های آموزش، مراحل یادگیری را می گذراند با همان داده ها یک مرحله تست نیز انجام می شود. اگر در حین تست با داده های آموزش سیستم دچار خطا شود به آن مقدار خطای آموزش گفته می شود. در زیر منحنی میزان خطای اموزش با مقادیر متغیر K آمده است:
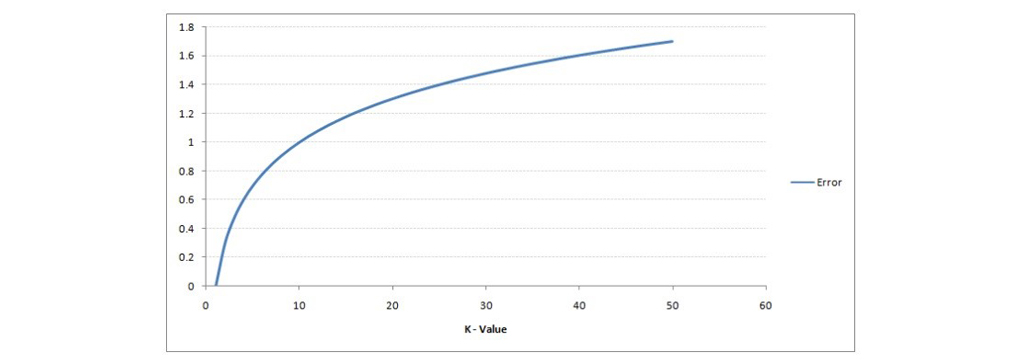
همانطور که مشاهده می کنید ، میزان خطا در K = 1 برای نمونه آموزشی همیشه صفر است. این به این دلیل است که نزدیکترین نقطه به هر نقطه داده آموزشی خود آن نقطه است. بنابراین پیش بینی همیشه با K = 1 دقیق است. اگر منحنی خطای اعتبارسنجی مشابه بود، انتخاب K ما 1 بود.
مقدار خطای اعتبار سنجی به میزان خطای سیستم در زمان تست سیستم با داده های جدید و یا به عبارتی داده های تست گفته می شود. در زیر منحنی خطای اعتبارسنجی با مقدار متفاوت K آمده است:
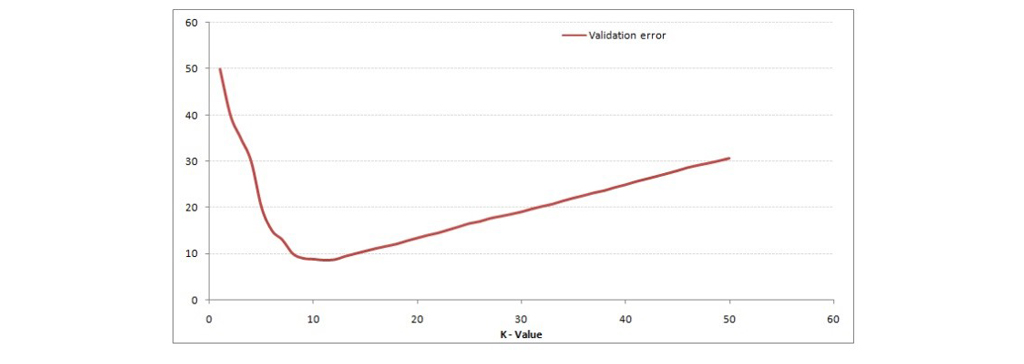
این باعث روشن شدن بیشتر داستان می شود. در K = 1 ، ما بیش از حد از مرزها استفاده می کردیم. بنابراین، میزان خطا در ابتدا کاهش می یابد و به حداقل می رسد. پس از نقطه حداقل، با افزایش K، خطا افزایش می یابد. برای به دست آوردن مقدار مطلوب K ، می توانید آموزش و اعتبارسنجی را از مجموعه داده اولیه جدا کنید. حالا منحنی خطای اعتبارسنجی را برای بدست آوردن مقدار مطلوب K رسم کنید. این مقدار K باید برای همه پیش بینی ها استفاده شود.
فرآیند الگوریتم K نزدیک ترین همسایگی
فرآیند الگوریتم K نزدیک ترین همسایگی شامل مراحل زیر اسـت:
1-در مرحله اول داده ها بارگذاری می شوند. به طور معمول 70 درصد داده ها را برای داده های آموزش در نظر می گیریم و 30 درصد داده ها را برای داده آزمون در نظر می گیریم.
2-مقدار k را در ابتدا تنظیم می کنیم.
3- برای بدست آوردن بهترین کلاس پیش بینی شده، از 1 تا کل نقاط داده آموزش را به سیستم یادگیر می دهیم و فاصله بین داده های آزمون و هر ردیف داده های آموزشی را محاسبه می کنیم. در اینجا ما از فاصله اقلیدسی به عنوان معیار فاصله خود استفاده می کنیم، زیرا این محبوب ترین روش است. معیارهای دیگر قابل استفاده عبارتند از چبیشف، کسینوس و غیره.
4- مجموعه فاصله ها و شاخص های مرتب شده را از کوچکترین تا بزرگترین (به ترتیب صعودی) بر اساس فاصلهها مرتب می کنیم.
5- اولین ورودی های K را از مجموعه مرتب شده انتخاب می کنیم
6 – برچسب های ورودی K انتخاب شده را دریافت می کنیم.
7- در صورت رگرسیون، میانگین برچسب های K را برمی گرداند و در صورت این که مسئله طبقه بندی باشد، حالت برچسب های K را بر می گرداند.
آماده سازی داده های مورد نیاز:
- مقیاس بندی داده ها: برای قرار دادن نقطه داده در فضای ویژگی چند بعدی، اگر همه ویژگی ها در مقیاس یکسان باشند بسیار خواهد بود. بنابراین نرمال سازی یا استاندارد سازی داده ها کمک بسیار مفیدی به نتیجه خواهد کرد.
- کاهش ابعاد: در صورت وجود ویژگی های زیاد، KNN ممکن است خوب کار نکند. از این رو تکنیک های کاهش ابعاد مانند انتخاب ویژگی، تجزیه و تحلیل مولفه های اصلی را می توان اجرا کرد.
- از دست دادن ارزش یک ویژگی: اگر از ویژگی های M (ویژگی های مورد سنجش)یک ویژگی برای یک مثال خاص در مجموعه آموزشی وجود نداشته باشد، نمی توانیم فاصله را از آن نقطه، تعیین یا محاسبه کنیم. بنابراین حذف آن سطر یا محاسبه مورد نیاز است.
کاربردهای الگوریتم K نزدیک ترین همسایه
از کاربردهای الگوریتم K نزدیک ترین همسایه یا کاربرد الگوریتم KNN میتوان به موارد زیر اشاره کرد:
استخراج متن: یکی از مهم ترین کاربرد های الگوریتم K نزدیک ترین همسایهمی توان به استخراج متن و الگو یابی اشاره کرد. از این روش برای تشخیص سرقت ادبی نیز می توان استفاده کرد.
کشاورزی: از الگوریتم K نزدیک ترین همسایه در تشخیص و دسته بندی مکانیزه میوه و محصولات کشاورزی می توان استفاده کرد.
سرمایه گذاری : برای دسته بندی و پیش بینی بازار سرمایه گذاری از این الگوریتم بسیار می توان استفاده کرد.
پزشکی: برای دسته بندی بیماران و تشخیص پیشرفت بیماری و بررسی اثر دارو می توان از توانمدی های الگوریتم K نزدیک ترین همسایه می توان استفاده کرد.
تشخیص چهره: تشخیص چهره و بحث پردازش تصویر یکی از مباحث داغ در دنیای تکنولوژی است. الگوریتم K نزدیک ترین همسایه یکی از الگوریتم های موفق در این زمینه بوده است.
دسته بندی مشتریان: یکی از مسائل مهم در داده کاوی دسته بندی مشتریان و دادن پیشنهاداتی متناسب با سبد خرید مشتریان است. الگوریتم K نزدیک ترین همسایه یکی از الگوریتم های مفید در این زمینه است.
سیستم های توصیه گر: امروزه اپلیکیشن های فروشگاهی و اپلیکیشن های مربوط به فیلم و موزیک کاملاً در بین افراد دنیا محبوب شده اند. یکی از مواردی که می تواند باعث شود که این سیستم ها از نظر جذب مخاطب از یک دیگر پیشی بگیرند، ارائه پیشنهاداتی نزدیک به سلیقه کاربر است. الگوریتم K نزدیک ترین همسایه در این زمینه بسیار موفق عمل کرده است.
مزایا الگوریتم K نزدیک ترین همسایه
از مزایا الگوریتم K نزدیک ترین همسایه یا مزایا الگوریتم KNN میتوان به موارد زیر اشاره کرد:
1-این الگوریتم بسیار ساده است و پیادسازی بسیار آسانی دارد.
2-تفسیر این الگوریتم و نتایج خروجی آن بسیار ساده است.
3- این الگوریتم دارای دقت بسیار بالای است.
4- الگوریتم K نزدیک ترین همسایه یک الگوریتم چند منظوره است و هم برای مسائل رگرسیون کاربرد دارد و هم مسائل طبقه بندی.
5- این الگوریتم قابلیت استفاده در طیف وسیعی از مسائل را دارد.
معایب الگوریتم K نزدیک ترین همسایه
از معایب الگوریتم K نزدیک ترین همسایه می توان به موارد زیر اشاره کرد:
1-در این الگوریتم زمان متوسط محاسبه کمی بالا است. که این یکی از نقاط ضعف این الگوریتم در داده های زیاد است.
2- این الگوریتم نیازمند حافظه زیاد است چون باید تمامی داده های قبلی را ذخیره کند.
3- این الگوریتم حساس به مقیاس داده است و اگر مقیاس بندی به درستی انجام نشود در نتایج تاثیر منفی می گذارد.
4- در این الگوریتم اگر K عدد بزرگی انتخاب شود پیش بینی کند و زمان افزایش پیدا می کند.
جمع بندی الگوریتم Knn یا الگوریتم K نزدیکترین همسایه
الگوریتم Knn یا الگوریتم K نزدیکترین همسایه یکی از ساده ترین الگوریتم های طبقه بندی است. حتی با وجود چنین سادگی، می تواند نتایج بسیار عالی را به همراه داشته باشد. الگوریتم KNN همچنین می تواند برای مسئل رگرسیون استفاده شود. تنها تفاوت متدولوژی مورد بحث استفاده از میانگین نزدیکترین همسایگان به جای رای دادن از نزدیکترین همسایگان خواهد بود. یکی از الگوریتم های مهم در بحث آموزش یادگیری ماشین و داده کاوی الگوریتم KNN است و دلیل آن سادگی بالا این الگوریتم است.
نویسنده: تیم پژوهش راهبرد




دیدگاه (2)
ممنون از مقاله خوبتون
سپاسگزاریم.