طبقه بندی در داده کاوی
سرفصل مطالب
طبقه بندی در داده کاوی
طبقه بندی در داده کاوی Classification : یکی از دانش هایی که در عصر حاضر بسیار مورد استقبال قرار گرفته داده کاوی است. به طور کلی به معنای کاوش در داده ها است که به اشکال مختلف برای به دست آوردن الگوها و کسب دانش در مورد الگوی حاکم بر این داده ها مورد استفاده قرار میگیرد. در فرآیند داده کاوی، ابتدا مجموعه داده های بزرگ مرتب میشود، سپس الگوها شناسایی میشود و روابط و تکنیکهایی برای انجام تجزیه و تحلیل داده ها و حل مسائل استفاده میشود. یکی از پرکاربردترین این روشها، تکنیک طبقه بندی یا Classification است که در این مقاله قصد بررسی مفاهیم اولیه و پایه ای طبقه بندی را داریم.
طبقه بندی داده ها
انسان ها دانش خود را از راه های گوناگونی می آموزند. گاهی یک راهنما یا یک معلم پاسخ صحیح مسئله را به ما می آموزد تا در موارد مشابه از آن استفاده کنیم. با الهام از این موضوع، یک روش یادگیری در علم شناسایی الگو، یادگیری با نظارت است. یکی از تکنیکهای پرکاربرد در یادگیری باناظر، تکنیک طبقه بندی است؛ تکنیک طبقه بندی یک روش تجزیه و تحلیل داده و یک روش کلاسیک داده کاوی مبتنی بر یادگیری ماشین است.
*یادآوری: یادگیری با ناظر: یکی از روش های داده کاوی، یادگیری با ناظر است. یادگیری الگوریتم های داده کاوی تحت نظارت میتوانند آنچه را که در گذشته آموخته شده است به منظور پیشبینی رویدادهای آینده با استفاده از مثالهای برچسب گذاری شده برای داده های جدید اعمال کنند. با شروع فرایند تجزیه و تحلیل یک مجموعه داده شناخته شده، الگوریتم، یک تابع برای پیش بینی مقادیر خروجی تولید میکند. سیستم میتواند اهداف هر ورودی جدید را پس از آموزش کافی فراهم کند. الگوریتم همچنین میتواند خروجی خود را با خروجی صحیحِ در نظر گرفته شده مقایسه کرده و به منظور تغییر مدل، خطای خود را پیدا کند. روشهایی که در یادگیری با ناظر استفاده میشوند خوشه بندی و رگرسیون است.
اصولاً از تکنیکهای طبقه بندی برای طبقه بندی هر داده در مجموعه ای از داده ها و اختصاص به یکی از مجموعه های از پیش تعیین شده کلاسها یا گروهها استفاده میشود. روش طبقه بندی از تکنیکهای ریاضی مانند درخت تصمیم، برنامه ریزی خطی، شبکه عصبی و آمار برای طبقه بندی استفاده میکند. به عبارتی طبقهبندی، فرایند یافتن مدلی که توصیف کننده کلاسها و مفاهیم داده است و داده ها را به گروههای مشخص تفکیک میکند. الگوریتم های طبقه بندی، قادر به یادگیری از تجربیات گذشته هستند و این یادگیری بر اساس تجربه نشان دهنده یک گام اساسی در تقلید از تواناییهای استقرایی مغز انسان است که بر اساس این توانایی مغز میتواند مسئله ی شناسایی یک گروه از دسته ها (زیرجمعیت ها) را انجام دهد.
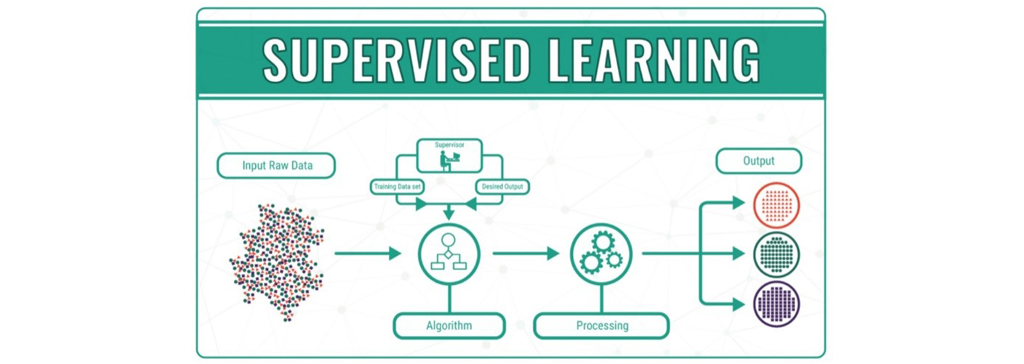
انجام فرایند طبقه بندی
فرایند طبقه بندی به این صورت است که براساس یک مجموعه آموزشی سیستم یاد میگیرد داده ها را به گروه های درست با کمترین خطا تقسیم بندی کند. مجموعه ی آموزش حاوی داده هایی است که دسته ی آنها مشخص است؛ هر الگو یا دسته یک برچسب (Label) دارد و داده هایی با برچسب هدف یکسان در یک گروه قرار میگیرند. هدف این روش، یادگیری تابعی است که الگوهای (بردارهای ویژگی) ورودی را به برچسبهای متناظرشان نگاشت میکند.
فرایند طبقه بندی دارای دو فاز اموزش (Train) و آزمون (Test) است. حدود 80% از داده های موجود در دیتاست را به عنوان داده ی آموزش انتخاب کرده و 20% داده های باقی مانده را برای آزمون و اعتبارسنجی انتخاب میکنیم. بدیهی است که برچسبهای واقعی الگوهای آموزشی از قبل داده شده اند. در فاز تست الگوهایی که برچسب آنها مشخص نیست به سیستم داده میشوند و سیستم طراحی شده به کمک تابع یادگرفته شده ی خود خروجی یا برچسب آنها را پیش بینی میکند.
انواع طبقه بندی
از انواع طبقه بندی می توان به موارد زیر اشاره کرد:
طبقه بندی دودویی یا باینری
Binary Classification یا طبقه بندی دودویی یا باینری: مسائلی از طبقه بندی که دارای دو برچسب کلاس هستند به طور مثل (صفر و یک یا yes , no) مسائل طبقه بندی دو کلاسه گفته میشود. مانند مسئله شناسایی ایمیل اسپم که دارای دو برچسب اسپم یا غیر اسپم است. یا در آزمایشات پزشکی، مشخص می شود یک بیمار دارای بیماری خاصی است یا خیر، بنابراین دارای دو برچسب بیمار یا غیر بیمار هستیم. در واقع در طبقه بندی دودویی، همانطور که در شکل زیر می بینید، تعدادی داده متعلق به یک کلاس است و تعدادی دیگر متعلق به کلاس دیگر است.
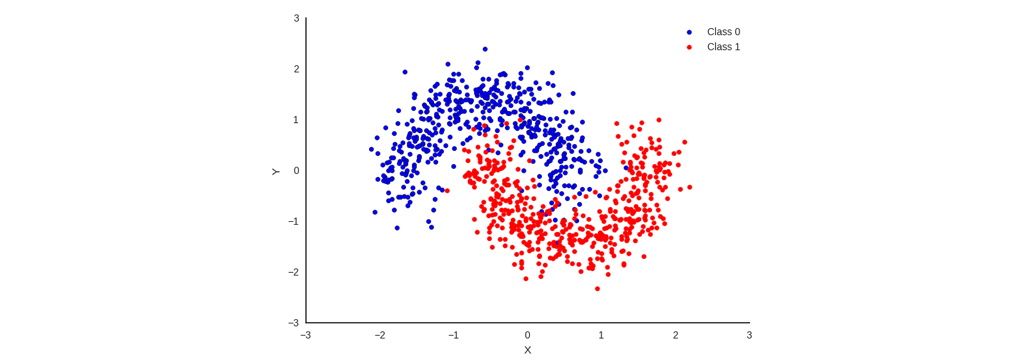
طبقه بندی چند کلاسه
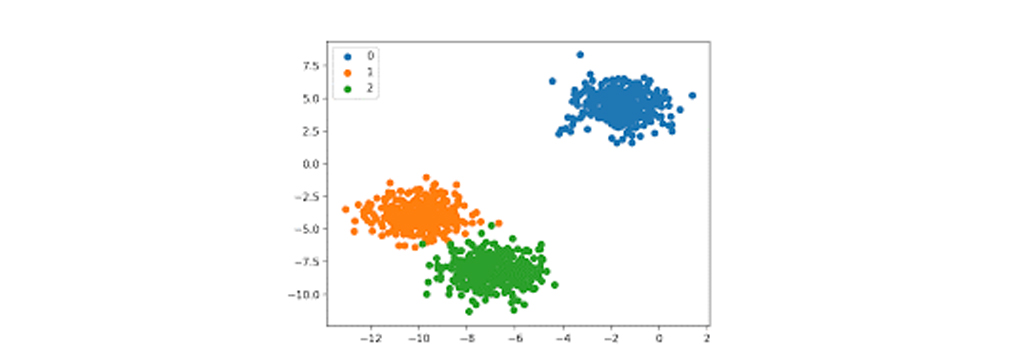
Multi-Class Classification یا طبقه بندی چند کلاسه: مسائلی از طبقه بندی را که داده ها متعلق به بیش از 2 کلاس باشد را مسائل چند کلاسه، گفته میشود. به طور مثال، در شکل زیر داده ها در 3 کلاس متفاوت قرار دارند. مانند طبقه بندی چهره، طبقه بندی گونه های گیاهی و غیره که به کلاسهای متفاوتی (بیش از 2 کلاس) تقسیم میشوند در دسته مسائل طبقه بندی چند کلاسه قرار میگیرد.
بررسی یک مثال طبقه بندی
فرض میکنیم دیتاست موجود مربوط به یکی از بانکها است. این بانک قصد دارد با بررسی اطلاعات مشتریان خود احتمال پرداخت نکردن وام را بررسی کند. اطلاعات موجود از مشتریان بدین شرح است:”سن”، “جنسیت”،”شغل”، “درامد” که توسط بانک جمع آوری شده است. مشتریان به دو گروه اول که به افرادی که وامشان را پرداخت کرده اند و گروه دوم افرادی که وامشان را پرداخت نکرده اند تقسیم میشوند. عددها کاملا فرضی و فقط برای بررسی یک مثال می باشد.
| کد مشتری | سن | جنسیت | شغل | درامد | وام پرداخت شده |
| #1 | 50 | زن | معلم | 1000 | بلی |
| #2 | 30 | مرد | کارمند | 800 | خیر |
| #3 | 45 | مرد | ازاد | 2000 | بلی |
| #4 | 25 | زن | کارمند | 1200 | خیر |
| #5 | 55 | زن | کارمند | 850 | بلی یا خیر * |
* پیش بینی اینکه ایا این مشتری با این مشخصات وام را پرداخت خواهد کرد یا خیر.
همان طور که با نگاهی گذرا به راحتی می توانیم جدول بالا را تفسیر کنیم؛ سطر یک از جدول بالا نشان دهنده این است که شخصی با کد مشتری(#1) یک خانم 50 ساله و معلم است و ماهانه حقوقی به مبلغ 1000 دریافت میکند و وام دریافتی خود را در زمان مشخص پرداخت کرده است. مقدار ستون اخر را به عنوان برچسب در نظر میگیریم و در مسئله مشتریان بانک به دو دسته ی 0 ,1 تقسیم میشوند. گروه با برچسب 0 افرادی هستند که وام خود را پرداخت نکردند و گروه با برچسب 1شامل افرادی است وام خود را پرداخت کردهاند. این 4 مورد از ۱۰ هزار مشتریِ مختلفی است که در پایگاه دادهی بانک ذخیره شدهاند.
همان طور که گفتیم این مسئله یک مسئله یادگیری با ناظر است ستونی که مقدار آن حاوی برچسب است که مشخص میکند که شخص وام را پرداخت میکند یا خیر این ستون توسط همان ناظر(مثلا رئیس بانک) تهیه شده است که در طبقه بندی استفاده می شود. اطلاعات در قالب جدول که در داده کاوی به آن ماتریس گفته میشود نمایش داده شده. هر ستون متعلق به یک شخص است که به آن رکورد یا یک نمونه گفته میشود. و هر ستون دارای مقادیری است که شامل سن، جنسیت، درامد و شغل است؛ هر کدام از این مقادیر یک ویژگی است و به هر ویژگی در مسائل طبقه بندی یک بُعد (Dimension) گفته میشود.
مسئله ی بالا دارای 4 ویژگی است یا به عبارتی 4 بُعدی است. ستون آخر ستون برچسب یا Label است، که مشخص میکند یک نمونهی خاص، در هر سطر به کدام دسته (Class) تعلق دارد. مسئله فوق یک مسئله دو کلاسه است. سپس بر روی این اطلاعات یکی از الگوریتم های یادگیری ماشین را اعمال می کنیم و از این ماتریس و ویژگیهای آن برای آموزش به ماشین و طبقه بندی استفاده میکنیم. حال اگر رکورد جدیدی بدون برچسب به الگوریتم یادگیری داده شود، الگوریتم میتواند مقدار برچسب آن را تشخیص دهد. هدف از انجام این کار به این صورت است که بانک با بررسی احتمال و پیش بینی اینکه آیا مشتری توان پرداخت وام خود را خواهد داشت یا خیر به بررسی شرایط میپردازد و بر اساس این نتایج میتواند تصمیم بگیرد با درخواست مشتری خود موافقت کند یا خیر یا پیشنهادات دیگری به مشتری خود ارائه دهد.
با استفاده از این روش میتوان در دیگر مسائل تجاری و مالی نیز از این روش استفاده کرد مانند پیشبینی ریزش مشتری یا پیشنهاد سبد خرید به مشتری مسائل مشابه هستند که با استفاده از طبقه بندی داده میتوان آن را طبقبندی کرد. اگر به این مبحث علاقمند شدید حتما مقاله “هوش تجاری چیست” را مطالعه فرمایید.
الگوریتم های طبقه بندی داده کاوی
از انواع الگوریتم های طبقه بندی داده کاوی می توان به موارد زیر اشاره کرد:
شبکههای عصبی Neural Networks (NN):
در راستای شبیهسازی رفتار محاسباتی مغز انسان، کارهای پژوهشی بسیاری از سوی متخصصین علوم رایانه، مهندسین و همچنین ریاضیدانها شروع شده است، که نتایج کار آنها، منجر به ایجاد شاخه ای در هوش مصنوعی به عنوان “شبکه های عصبی” شده است. در مبحث شبکه های عصبی مصنوعی، مدل های ریاضی و نرمافزاری متعددی با الهام گرفتن از مغز انسان پیشنهاد شدهاند.
این شبکه با الهام از شبکه نورونهای مغز انسان، سعی در توسعه پردازش اطلاعات دارد. در واقع شبکه عصبی کمک میکند بهجای دیکته کردن کاری که باید انجام شود به کامپیوتر (برنامهنویسی) خود کامپیوتر را برای دادن واکنش مناسب به اتفاقات آموزش دهیم. هر نورون در این شبکه یک عنصر پردازشی بوده و در کنار دیگر عناصر پردازشی به حل مسائل مختلف میپردازد.
درخت تصمیم(DT) Decision Tree :
درخت تصمیم یک ابزار برای پشتیبانی از تصمیم است که از درختها برای مدل کردن استفاده میکند. درخت تصمیم بهطور معمول در تحقیقها و عملیات مختلف استفاده میشود. بهطور خاص در آنالیز تصمیم، برای مشخص کردن استراتژی که با بیشترین احتمال به هدف برسد بکار میرود.
K–نزدیکترین همسایه (KNN):
در الگوریتم نزدیکترین همسایگی بر اساس دادههای اولیه، بردارهایی در یک فضای چند بعدی هستند که هر کدام شامل برچسبی به نام دسته میباشند. در فاز طبقهبندی، k یک ثابت توسط کاربر تعریف میشود و بردار بدون برچسب (نقطه تست) از دسته ای است که بیشترین تعداد را در k نزدیکترین همسایه آن نقطه داشته باشد قرار میدهد. به این ترتیب برچسب نقطه تست نیز مشخص میشود. معیار فاصله برای متغیرهای پیوسته معمولاً فاصله اقلیدسی است.
ماشین بردار پشتیبان (SVM) Support Vector Machine :
ماشین بردار پشتیبان، یک دسته بند یا مرزی است که با معیار قرار دادن بردارهای پشتیبان (نقاطی انتخاب شده از بین داده ها)، بهترین دسته بندی و تفکیک خطی بین داده ها را برای ما مشخص می کند. ماشین بردار پشتیبان به طور قطع یک طبقه بند بسیار قوی برای تفکیک داده ای پیچیده است.
رگرسیون Regression :
رگرسیون خطی اغلب برای کشف مدل رابطهی خطی بین متغیرها استفاده میشود. در این الگوریتم با استفاده از چند متغییر که مقدار انها مستقل از یکدیگر است برای پیشبینی مقدار متغییر هدف استفاده می شود. هدف از انجام تحلیل رگرسیون شناسایی مدل خطی بین این متغیرها است.
مزیت های طبقه بندی
مزیت های طبقه بندی : روشهای مبتنی بر طبقه بندی روشهایی مقرون به صرفه از نظر اقتصادی و کارآمد است و با بکاربردن این روشها میتوان اطلاعاتی دقیق و درست بدست آورد چون دانش بدست آمده از روی اطلاعات دقیق و مربوط به همان کسب و کار است. و این دانش باعث ایجاد تحولی بزرگ در دنیای تجارت و تبلیغات خواهد شد. به راستی هوش تجاری چیست؟
کاربردهایی از طبقه بندی
کاربردهای طبقه بندی در داده کاوی : امروزه از یادگیری ماشین در زمینه های مختلف استفاده میشود. به دلیل حجم انبوه داده های موجود، برای بر طرف کردن مسائل نیاز به محاسبات سنگین و زمانبر است بنابراین استفاده از الگوریتم های طبقه بندی در یادگیری ماشین برای حل مسائل دنیای واقعی استفاده میشود. در ذیل به به بررسی چند مورد میپردازیم:
پردازش تصویر و تشخیص چهره:
یکی از رایجترین کاربردهای یادگیری ماشین شناسایی تصویر است. در موقعیتهای زیادی نیاز به طبقه بندی تصاویر داریم. از یادگیری ماشین نیز میتوان در شناسایی چهره نیز استفاده کرد. در یک دیتابیس برای هر فرد یک دسته بندی جدا وجود دارد و الگوریتمهای یادگیری ماشین با توجه به این تصاویر به تشخیص هویت میپردازند. از یادگیری ماشین هم چنین در تشخیص دست خط در نوشته های معمولی یا نسخ خطی چاپ شده نیز استفاده میشود.

فیلتر کردن شبکه های اجتماعی و ایمیلها:
برای طبقه بندی و تشخیص مطالب هرز در شبکه های اجتماعی از طبقه بندهای یادگیری ماشین میتوان استفاده کرد.
تشخیص پزشکی وبررسی تاثیر دارو:
تشخیص اینکه آیا بیمار مبتلا به یک بیماری است یا خیر و اینکه یک دارو روی دسته ای از افراد مبتلا به یک بیماری اثر میگذارد یا خیر.
پیشبینی آب و هوا:
با استفاده از اطلاعات موجود شرایط جوی از روزهای قبل میتوان وضعیت روزهای کنونی را پیشبینی کرد. برای مثال فردا باران میبارد یا خیر.
بررسی تقلب و جعل:
با داشتن تعداد زیادی از نمونه ها مانند نمونه امضا و دست خط میتوان به ماشینها به گونه ای اموزش داد که از کلاهبرداری و تقلب جلوگیری کنند و این بسیار در سیستمهای بانکی و مالی پرکاربرد است.
شناسایی صدا:
یکی دیگر از کاربردهای یادگیری ماشین تبدیل گفتار به متن میباشد. این تکنیک به شناسایی گفتار معروف است. به کمک شناسایی گفتار یک نرم افزار میتواند کلمات موجود در یک گفتار را تشخیص دهد و آن را به یک فایل متنی تبدیل کند. شناسایی گفتار میتواند در برنامههایی کاربرد داشته باشد که رابط تعاملی صوتی دارند و یا قابلیت جستجی صوتی و… دارند.
کاربردهایی مانند سيستم هاي پيشنهادگر، مرتب سازي نتايج موتورهاي جستجو، تشخيص چهره خندان براي عکاسي خودکار، همگي نمونه هاي ديگري از کاربردهاي يادگيري ماشين هستند.
جایگاه الگوریتمهای طبقه بندی در هوش تجاری
جایگاه الگوریتمهای طبقه بندی در هوش تجاری : هوش تجاری مجموعه ای از نرم افزارها و ابزار آنالیز داده است، که با بررسی داده های یک شرکت میتواند میزان سود و زیان و دلایل آن را مشخص کند. از آنجایی که آنالیز داده ها میتواند مدیران را در اتخاذ تصمیمهای بسیار بزرگ یاری کند، شرکتها نیازمند استفاده از چنین سیستم های هوشمندی هستند. برای پیاده سازی هوش تجاری می بایست، کل مجموعه ی همکاریها و دانش لازم را داشته باشد، در غیر این صورت نتیجه مورد انتظار حاصل نخواهد شد. یکی از این دانشهای بسیار مهم و کاربردی در این زمینه بکاربردن روشهای داده کاوی است. تکنیکهای طبقه بندی در حل مسائل یادگیری با ناظر بسیار کاربرد دارد و در مسائلی مانند تحلیل سبد مشتریان، تعیین شرایط تبلیغات برای اثرگذاری بیشتر، تحلیل صنت مد و غیره کاربرد دارد تا بتوان بهترین و دقیقترین مشاوره را به مدیران صنایع داد تا بتوانند بهترین تصمیمها را برای ادامه مسیر را انتخاب کنند.
جمع بندی مقاله طبقه بندی در داده کاوی
جمع بندی طبقه بندی در داده کاوی: امروزه انسان کاربردهاي بسيار زيادي از هوش مصنوعي و يادگيري ماشين را در زندگي روزانه خود بکار میبرد. این ابزارها برای این به وجود میآیند که برای تصمیمگیری و مشاوره در کنار انسان باشند. بسیاری از کارها را به جای انسان انجام دهند. در سالهای نه چندان دور شاهد پیشرفت هر چه بیشتر سیستم های یادگیری ماشین خواهیم بود.
برای اینکه این سیستمها هر چه بهتر بتوانند با انسان ارتباط برقرار کنند باید بهتر و دقیق تر بتوانند اطلاعات را تجزیه و تحلیل کنند و یکی از این روشهای تجزیه و تحلیل که در این مطلب به آن پرداخته شد بحث طبقه بندی داده ها است زیرا با این سرعتی که جهان در حال پیشرفت است تا چند سال آینده با حجم عظیمی از داده مواجه خواهیم بود که خود میتواند یک مزیت بزرگ برای آینده باشد و این اطلاعات موجود و الگوهای نهفته در درونشان خود بهترین مشاور برای آینده هر کسب و کاری خواهند بود.
نویسنده: تیم پژوهش راهبرد


دیدگاه (2)
سلام ممنون از مطلب جامع و کاملی که ارائه دادید، فقط امکانش هست منابع رو هم ذکر کنید؟
سپاسگزاریم. بله حتما. در اکثر مقاله ها ، منابع را در انتها قرار دادیم. در آپدیت بعدی حتما این مورد را بررسی خواهیم کرد.