الگوریتم Boosting
سرفصل مطالب
الگوریتم Boosting یا الگوریتم بوستینگ
بسیاری از تحلیلگران اصطلاح ” Boosting ” که در علم داده استفاده می شود را به اشتباه تفسیر می کنند. Boosting به مدل های یادگیری ماشین قدرت می دهد تا دقت پیش بینی آن ها را بهبود بخشد. الگوریتم های Boosting یکی از پرکاربردترین الگوریتم ها در مسابقات علم داده است. در این مقاله، نحوه عملکرد الگوریتم Boosting را به روش بسیار ساده توضیح خواهیم داد. پس با راهبرد همراه باشید. این الگوریتم تقویت کننده برای اولین بار توسط Freund و Schapire در سال 1997 با الگوریتم AdaBoost معرفی شد، و از آن زمان، Boosting یک تکنیک رایج برای حل مسائل طبقه بندی باینری بوده است.
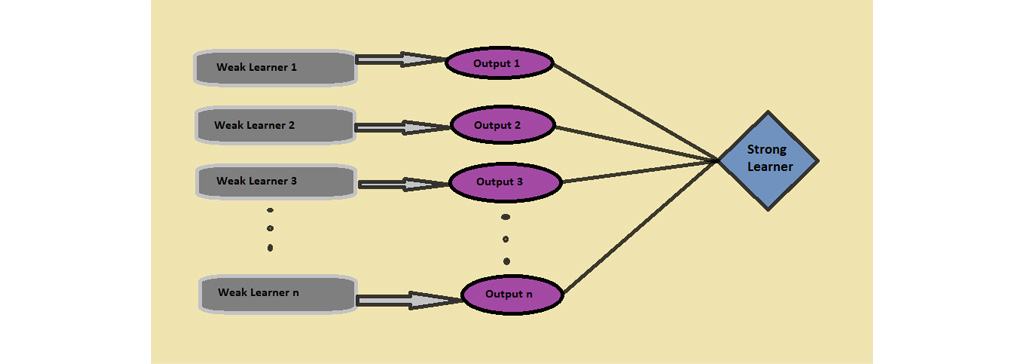
Boosting الگوریتم ها در یادگیری ماشین چیست؟
Boosting الگوریتم ها در یادگیری ماشین چیست؟ اصطلاح ” Boosting” به خانواده ای از الگوریتم ها اشاره دارد که مدل های یادگیری ماشین که عملکرد ضعیفی دارند را به مدل های قوی تبدیل می کند. بیایید با حل مشکل شناسایی ایمیل های اسپم، این تعریف را به تفصیل بیان کنیم: یک مدل یادگیری چگونه یک ایمیل را به عنوان SPAM طبقه بندی می کند؟ رویکرد اولیه مدل ما شناسایی ایمیل های “هرزنامه” و “غیر اسپم” با استفاده از معیارهای زیر خواهد بود.
1- ایمیل فقط یک فایل تصویری (تصویر تبلیغاتی) دارد، این یک SPAM است.
2- ایمیل فقط حاوی یک لینک است.این ایمیل یک SPAM است.
3- متن ایمیل شامل جمله ای مانند “شما یک جایزه $ xxxxxx برنده شدید” ، این ایمیل یک SPAM است.
4- ایمیل از دامنه رسمی ما “” Analyticsvidhya.com، نه SPAM نیست.
در بالا، قوانین متعددی برای طبقه بندی یک ایمیل به “اسپم” یا “غیر اسپم” تعریف شد. اما، آیا فکر می کنید این قوانین به تنهایی برای طبقه بندی موفقیت آمیز یک ایمیل به اندازه کافی قوی هستند؟
خیر به طور جداگانه، این قوانین به اندازه ای قدرتمند نیستند که بتوانند یک ایمیل را به عنوان “اسپم” یا “غیر اسپم” طبقه بندی کنند. بنابراین، این قوانین به عنوان یک مدل یادگیری ضعیف نامیده می شوند. برای تبدیل یک مدل یادگیری ضعیف به یک مدل یادگیری قوی، می توانیم از چند روش استفاده کنیم.
- استفاده از میانگین/ میانگین وزنی
- در نظر گرفتن پیش بینی با رای بالاتر( به عنوان مثال: در بالا، 5 مدل یادگیر ضعیف داریم از بین این 5 مد، 3 مدل به یک ایمیل رای “” SPAM و 2مدل به این ایمیل رای SPAM” ” نداده اند. در این مثال چون تعداد بیشتری به این ایمیل رای SPAM”” داده اند این ایمیل را به عنوان SPAM”” در نظر می گیریم.
الگوریتم های Boosting چگونه کار می کند؟
الگوریتم های Boosting چگونه کار می کند؟ در حال حاضر ما می دانیم که، Boosting ترکیبی از مدل های یادگیری ضعیف است، از جمله مدل یادگیری پایه که برای ایجاد یک قانون قوی به کار می رود. در ادامه بررسی می کنیم که چگونه می توانیم قوانین ضعیف را تقویت کنیم. برای یافتن قانون ضعیف، از الگوریتم های یادگیری پایه با توزیع های متفاوت برای داده ها استفاده می کنیم. هر بار که الگوریتم یادگیری پایه اعمال می شود، یک قانون پیش بینی ضعیف جدید ایجاد می کند. این یک فرایند تکراری است. پس از تکرارهای زیاد، الگوریتم Boosting این قوانین ضعیف را در یک قانون پیش بینی قوی واحد ترکیب می کند. برای انتخاب توزیع مناسب، مراحل زیر را دنبال کنید:
مرحله 1: مدل یادگیرنده پایه همه توزیع ها را انجام می دهد و وزن یا توجه یکسانی را به هر داده اختصاص می دهد.
مرحله 2: در صورت بروز هرگونه خطای پیش بینی ناشی از الگوریتم یادگیری پایه اولیه، توجه بیشتری به داده های دارای خطای پیش بینی می کند. سپس، الگوریتم یادگیری پایه بعدی را اعمال می کنیم.
مرحله 3: مرحله 2 را تا رسیدن به حد الگوریتم یادگیری پایه یا دستیابی به دقت بیشتر تکرار می کند.
در نهایت، خروجی های مدل یادگیری ضعیف را ترکیب کرده و یک یادگیرنده قوی ایجاد می کند که در نهایت قدرت پیش بینی مدل را بهبود می بخشد. افزایش تمرکز بیشتری بر روی نمونه هایی دارد که با طبقه بندی نادرست طبقه بندی شده یا با رعایت قوانین ضعیف دارای خطاهای بیشتری هستند.
بر خلاف بسیاری از مدل های یادگیری ماشین که بر پیش بینی با کیفیت بالا که توسط یک مدل واحد متمرکز شده است، الگوریتم های Boosting به دنبال بهبود قدرت پیش بینی با آموزش یک سری مدل های ضعیف هستند که هر یک نقاط ضعف مدل های قبلی خود را جبران می کند.
الگوریتم Boosting یک الگوریتم عمومی است نه یک مدل خاص، و این مسئله بسیار مهم است. الگوریتم Boosting به شما نیاز دارد که یک مدل ضعیف (مانند رگرسیون، درخت تصمیم گیری سطحی و غیره) را مشخص کنید و سپس آن را بهبود بخشید.
انواع الگوریتم Boosting
1- الگوریتم Adaptive Boosting (AdaBoost)
2- الگوریتم Gradient Boosting
3- الگوریتم XGBoost
الگوریتم AdaBoost
الگوریتم AdaBoost یک الگوریتم تقویت خاص است که برای مشکلات طبقه بندی توسعه یافته است (همچنین AdaBoost گسسته نیز نامیده می شود).
در هر تکرار، AdaBoost نقاط داده های طبقه بندی نشده را مشخص می کند، وزن آن ها را افزایش می دهد (و وزن نقاط صحیح را کاهش می دهد)، به طوری که طبقه بندی کننده بعدی توجه بیشتری به آن ها می کند. شکل زیر نحوه تاثیر وزن ها بر عملکرد یک تصمیم گیری ساده (درخت با عمق 1).
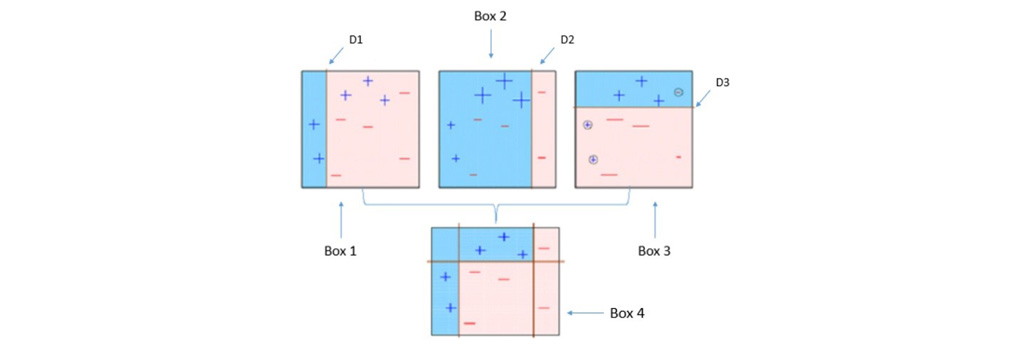 AdaBoost دنباله ای از مدل ها را با وزن نمونه افزایش یافته، آموزش می دهد و ضرایب اطمینان را برای طبقه بندی کننده های فردی بر اساس خطا ها ایجاد می کند. خطاهای کم منجر به ایجاد آلفا بزرگ می شود که به معنی اهمیت بیشتر در رای گیری است. در زیر به بررسی شکل بالا می پردازیم.
AdaBoost دنباله ای از مدل ها را با وزن نمونه افزایش یافته، آموزش می دهد و ضرایب اطمینان را برای طبقه بندی کننده های فردی بر اساس خطا ها ایجاد می کند. خطاهای کم منجر به ایجاد آلفا بزرگ می شود که به معنی اهمیت بیشتر در رای گیری است. در زیر به بررسی شکل بالا می پردازیم.
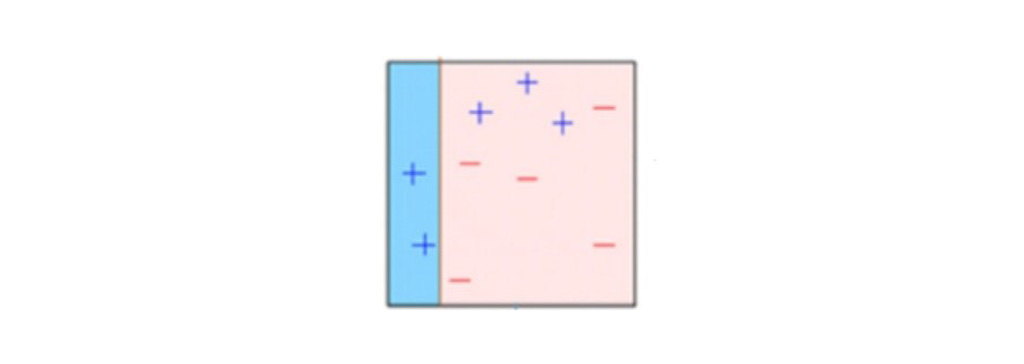
در شکل زیر مشاهده می کنید که ما وزن های مساوی را برای هر نقطه داده اختصاص داده ایم و یک مدل تصمیم گیرنده برای طبقه بندی آن ها به عنوان + (بعلاوه) یا – (منهای) اعمال کرده ایم. تصمیم گیرنده(D1)یک خط عمودی در سمت چپ ایجاد کرده است تا نقاط داده را طبقه بندی کند. ما می بینیم که این خط عمودی سه + (بعلاوه) را به عنوان – (منهای) به اشتباه پیش بینی کرده است. در چنین حالتی، الگوریتم وزنه های بالاتری را به این سه + (بعلاوه) اختصاص می دهد و یک مدل تصمیم گیرنده دیگر اعمال می کنیم.
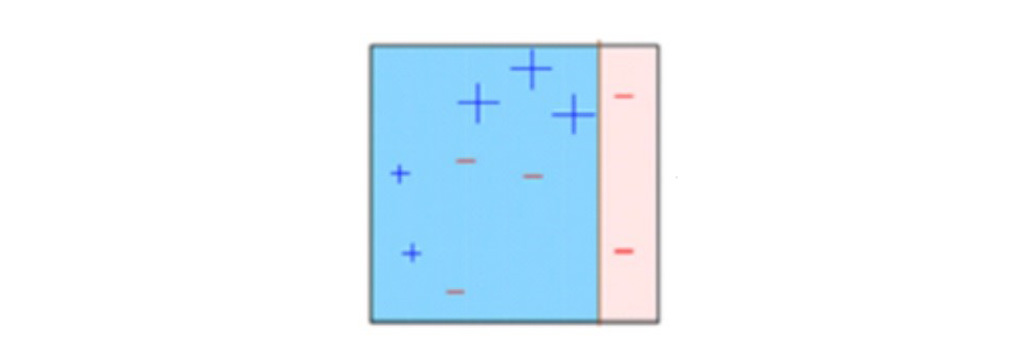
 در شکل زیر می بینید که اندازه سه نادرست + (به علاوه) در مقایسه با بقیه نقاط داده بزرگتر است. در این مورد، تصمیم گیرنده دوم (D2)سعی می کند آن ها را به درستی پیش بینی کند. در حال حاضر، یک خط عمودی (D2)در سمت راست در نظر بگیرد و این کادر سه طبقه بندی اشتباه ( + بعلاوه) را به درستی طبقه بندی کرده است. اما باز هم، باعث اشتباه در طبقه بندی شده است. این بار با سه -(منهای) را به اشتباه پیش بینی کرده است. باز هم، وزن بیشتری را به سه – (منهای) اختصاص می دهیم و یک تصمیم گیرنده دیگر را اعمال می کنیم.
در شکل زیر می بینید که اندازه سه نادرست + (به علاوه) در مقایسه با بقیه نقاط داده بزرگتر است. در این مورد، تصمیم گیرنده دوم (D2)سعی می کند آن ها را به درستی پیش بینی کند. در حال حاضر، یک خط عمودی (D2)در سمت راست در نظر بگیرد و این کادر سه طبقه بندی اشتباه ( + بعلاوه) را به درستی طبقه بندی کرده است. اما باز هم، باعث اشتباه در طبقه بندی شده است. این بار با سه -(منهای) را به اشتباه پیش بینی کرده است. باز هم، وزن بیشتری را به سه – (منهای) اختصاص می دهیم و یک تصمیم گیرنده دیگر را اعمال می کنیم.
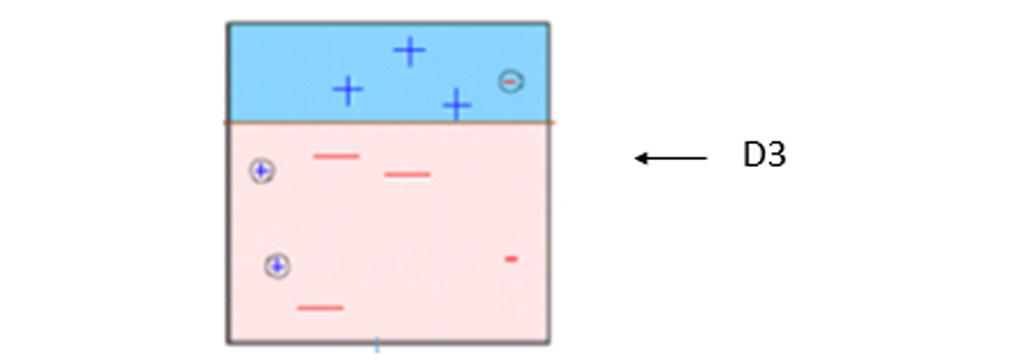
 در شکل زیر به سه – (منهای) وزنه های بیشتری داده می شود. برای پیش بینی درست این مشاهدات اشتباه طبقه بندی شده، یک تصمیم تصمیم گیر (D3) اعمال می شود. این بار یک خط افقی برای طبقه بندی + (بعلاوه) و-(منهای) بر اساس وزن بیشتر مشاهدات اشتباه طبقه بندی شده ایجاد می شود.
در شکل زیر به سه – (منهای) وزنه های بیشتری داده می شود. برای پیش بینی درست این مشاهدات اشتباه طبقه بندی شده، یک تصمیم تصمیم گیر (D3) اعمال می شود. این بار یک خط افقی برای طبقه بندی + (بعلاوه) و-(منهای) بر اساس وزن بیشتر مشاهدات اشتباه طبقه بندی شده ایجاد می شود.
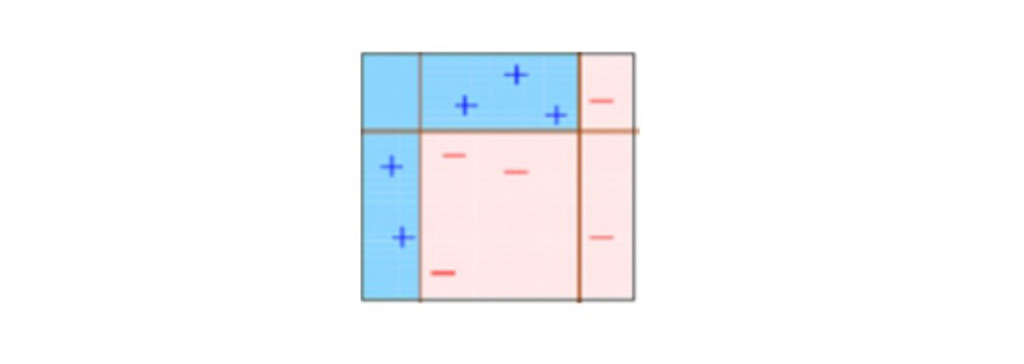
 در شکل زیر، ما D1 ، D2 و D3 را با هم ترکیب کرده ایم تا در مقایسه با هر تصمیم گیرنده ضعیف، یک پیش بینی قوی با قوانین پیچیده ایجاد کنیم. می بینید که این الگوریتم این مشاهدات را در مقایسه با سایر یادگیرنده های ضعیف به خوبی طبقه بندی کرده است.
در شکل زیر، ما D1 ، D2 و D3 را با هم ترکیب کرده ایم تا در مقایسه با هر تصمیم گیرنده ضعیف، یک پیش بینی قوی با قوانین پیچیده ایجاد کنیم. می بینید که این الگوریتم این مشاهدات را در مقایسه با سایر یادگیرنده های ضعیف به خوبی طبقه بندی کرده است.
 (Adaptive Boosting) AdaBoost: با روش مشابهی که در بالا توضیح داده شد کار می کند. این برنامه دنباله ای از مدل های یادگیری ضعیف را بر روی داده های آموزشی مختلف تست می کند. با پیش بینی مجموعه داده اصلی شروع می شود و وزن مساوی به هر داده اختصاص می دهد. اگر پیش بینی با استفاده از اولین یادگیرنده نادرست باشد، به داده هایی که به اشتباه پیش بینی شده اند، اهمیت بیشتری می دهد. به عنوان یک فرایند تکراری، به افزودن مدل های یادگیری (ها) تا رسیدن به محدودیت در تعداد مدل ها یا دقت ادامه می دهد. ما می توانیم از الگوریتم های AdaBoost برای مشکل طبقه بندی و رگرسیون استفاده کنیم.
(Adaptive Boosting) AdaBoost: با روش مشابهی که در بالا توضیح داده شد کار می کند. این برنامه دنباله ای از مدل های یادگیری ضعیف را بر روی داده های آموزشی مختلف تست می کند. با پیش بینی مجموعه داده اصلی شروع می شود و وزن مساوی به هر داده اختصاص می دهد. اگر پیش بینی با استفاده از اولین یادگیرنده نادرست باشد، به داده هایی که به اشتباه پیش بینی شده اند، اهمیت بیشتری می دهد. به عنوان یک فرایند تکراری، به افزودن مدل های یادگیری (ها) تا رسیدن به محدودیت در تعداد مدل ها یا دقت ادامه می دهد. ما می توانیم از الگوریتم های AdaBoost برای مشکل طبقه بندی و رگرسیون استفاده کنیم.
الگوریتم Gradient Boosting
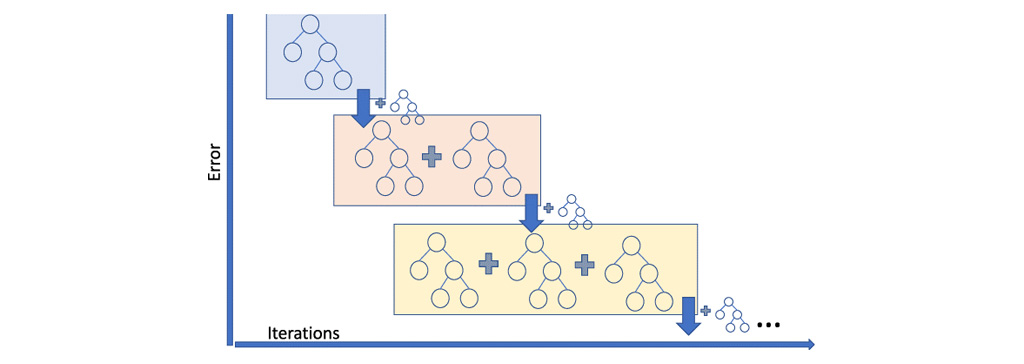
در الگوریتم Gradient Boosting، ما چندین مدل را به صورت متوالی آموزش می دهیم و برای هر مدل جدید، مدل به تدریج با استفاده از روش Gradient Descent تابع ضرر را به حداقل می رساند. الگوریتم Gradient Tree Boosting درختان تصمیم گیری را به عنوان ضعیف ترین مدل های یاگیری در نظر می گیرد. زیرا گره های یک درخت تصمیم، شاخه های متفاوتی از ویژگی ها را برای انتخاب بهترین پیش بینی در نظر می گیرند، به این معنی که همه درختان یکسان نیستند. از این رو، آن ها می توانند خروجی های متفاوتی از داده ها را در تمام مدت ضبط کنند. الگوریتم تقویت درخت گرادیان به طور متوالی ساخته می شود زیرا برای هر درخت جدید، مدل خطاهای آخرین درخت را در نظر می گیرد و تصمیم هر درخت پی در پی بر اساس اشتباهات درخت قبلی ساخته می شود.
با توجه به شکل زیر در زمان اموزش مدل های متوالی در هر تکرار به سمتی پیش می رویم که خطای پیش بینی کم شود و باعث ایجاد یک یادگیرنده قوی می شود.
 الگوریتم XGBoost
الگوریتم XGBoost
 الگوریتم XGBoost
الگوریتم XGBoostالگوریتم XGBoost ، مخفف Extreme Gradient Boosting ، یک نسخه متفاوت از الگوریتم Gradient Boosting است و روش کار هر دو تقریباً یکسان است. یک نکته مهم در XGBoost این است که پردازش موازی را در سطح گره پیاده می کند و از الگوریتم Gradient Boosting قوی تر و سریعتر است. XGBoost با تنظیم پارامترهای فوق العاده الگوریتم XGBoost ، over fit را کاهش می دهد و عملکرد کلی را با استفاده از تکنیک های مختلف منظم سازی بهبود می بخشد. یکی از نکات مهم در مورد XGBoost این است که نیازی نیست نگران مقادیر از دست رفته در مجموعه داده باشیم زیرا در طول فرآیند آموزش، خود مدل یاد می گیرد که مقادیر گم شده، یعنی گره چپ یا گره صحیح را در کجا قرار دهد.
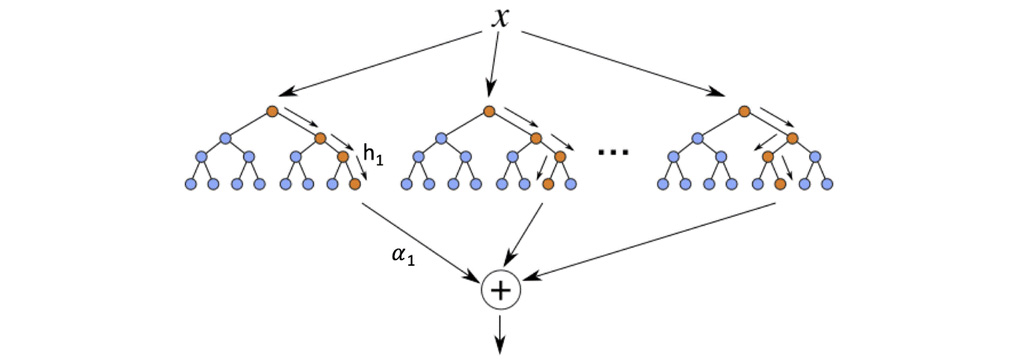 در شکل بالا درخت های مختلف و با تفاوت هایی که مشاهده می کنید تشکیل می شود و سپس مدل به پیش بینی بیشترین مقدار می پردازد.
در شکل بالا درخت های مختلف و با تفاوت هایی که مشاهده می کنید تشکیل می شود و سپس مدل به پیش بینی بیشترین مقدار می پردازد.
مزایا الگوریتم Boosting
از مزایا الگوریتم Boosting می توان به موارد زیر اشاره کرد:
تفسیر آسان: Boosting اساساً یک مدل گروهی است ، بنابراین تفسیر پیش بینی آن آسان است.
قدرت پیش بینی قوی: الگوریتم Boosting توانایی پیش بینی بالایی دارد به دلیل اینکه به جای تکیه بر نتایج یک یادگیرنده به نتایج چند یادگیرند توجه می کند.
الگوریتم Boosting در برابر over fit مقاوم است. زیرا داده ها را با توزیع های متفاوت و با ترتیب های متفاوت آموزش می دهد.
معایب الگوریتم Boosting
از معایب الگوریتم Boosting می توان به موارد زیر اشاره کرد:
حساس به نویزها: از آنجایی که هر طبقه بندی کننده ضعیف برای رفع نواقص پیشینیان خود اختصاص داده شده است، ممکن است مدل بیش از حد به داده های پرت و نویز ها توجه کند و این خود تاثیر منفی روی نتیجه بگذارد.
مقیاس بندی سخت است: از آنجا که هر مدل یادگیرنده بر اساس نسخه های قبلی خود ساخته شده است، به سختی می توان این روند را موازی کرد.
جمع بندی الگوریتم Boosting
الگوریتم Boosting یک روش یادگیری است که برای رفع ضعف یادگیرنده های ماشین ایجاد شده. این روش برای رفع مشکلات طبقه بندی و رگرسیون به کار می رود. در این روش با ترکیب موازی یا متوالی تلاش می شود تا خطا حد زیادی کاهش پیدا کند و بتوان طبقه بندی را به درست ترین شکل ممکن انجام داد. روش Boosting در داده کاوی بسیار مورد استقبال قرار می گیرد و از نتایج بسیار قوی این الگوریتم استفاده های فراوانی می شود. یکی از کاربرد های مهم این الگوریتم تشخیص چهره است. به دلیل اهمیت این موضوع استفاده از چند یادگیرنده به جای یک یادگیرنده توصیه می شود.
نویسنده: تیم پژوهش راهبرد


هیچ نظری وجود ندارد