رگرسیون Ridge ریج (Ridge Regression)
سرفصل مطالب
رگرسیون ریج (Ridge Regression)
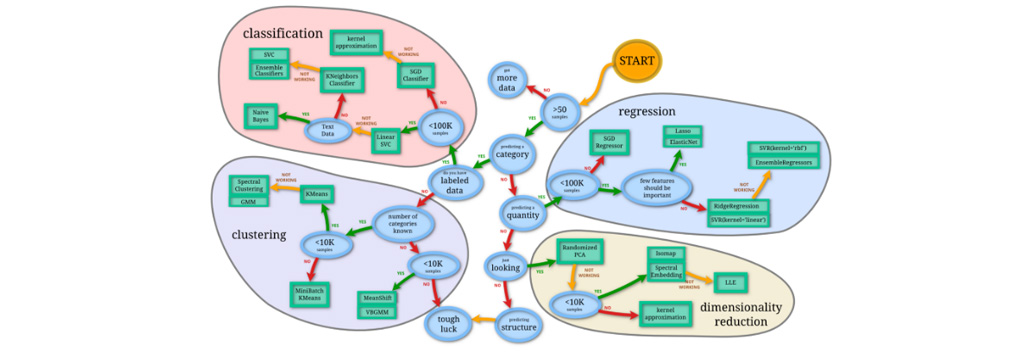
مسائل یادگیری تحت نظارت را می توان بیشتر در دسته بندی و رگرسیون جای داد. برخلاف مسائل طبقه بندی، رگرسیون وظیفه پیش بینی مقدار پیوسته (مانند وزن و درآمد) را دارد. همانطور که از نامش پیداست، رگرسیون ریج در دسته دوم قرار می گیرد. Ridge Regression در حل مسائلی که کمتر از صد هزار نمونه (تعداد نمونه کم) دارید یا هنگامی که پارامترهای بیشتری نسبت به نمونه دارید، بسیار مفید است. رگرسیون یک روش مدل سازی است که شامل پیش بینی یک مقدار عددی است با توجه به یک ورودی که دریافت می کند. رگرسیون خطی الگوریتم استاندارد رگرسیون است که رابطه خطی بین ورودی ها و متغیر هدف را در نظر می گیرد.
 رگرسیون ریج (رگرسیون Ridge)
رگرسیون ریج (رگرسیون Ridge)
در مدل رگرسیون خطی، برای پیش بینی درست مقادیر از یک تابع خطا استفاده شده که به طور معمول این تابع «مجموع مربعات خطا» (Sum of Square Error) را کمینه می کنند. رگرسیون Ridge که یک افزونه از رگرسیون خطی است از ترکیب تابع مجموع مربعات خطا و مقدار جریمه هر پارامتر، یک تابع جدید ایجاد میشود که به منطور پیش بینی مقادیر پارامترهای مدل رگرسیونی استفاده می شود.
Ridge Regression یک نوع محبوب از رگرسیون خطی منظم است که شامل مجازات L2 می شود. این امر بر کاهش ضرایب آن دسته از متغیرهای ورودی تأثیر چندانی در کار پیش بینی ندارد. در این مطلب، به بررسی نحوه توسعه و ارزیابی مدل های Ridge Regression می پردازیم. موضوعاتی را که در این مطلب بررسی خواهیم کرد.
- Ridge Regression یک مدل توسعه یافته از رگرسیون خطی است که نسبت پنالتی را به تابع ضرر در طول آموزش اضافه می کند.
- نحوه ارزیابی مدل Ridge Regression
- استفاده از مدل نهایی برای پیش بینی داده های جدید.
رگرسیون خطی
رگرسیون خطی به مدلی گفته می شود که رابطه ای خطی بین متغیرهای ورودی و متغیر هدف ایجاد می کند. با یک متغیر ورودی واحد، این رابطه یک خط است و در ابعاد بالاتر، این رابطه را می توان یک مدل دانست که متغیرهای ورودی را به متغیر هدف متصل می کند. ضرایب مدل از طریق یک فرآیند بهینه سازی که به دنبال به حداقل رساندن خطای مربع بین مقادیر پیش بینی شده( ŷ) و مقادیر مورد انتظار(y) است، یافت می شود.
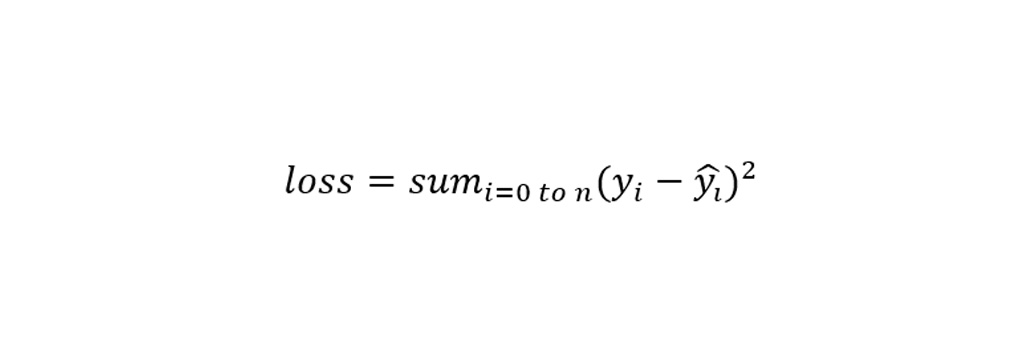 مقدار ¡у به مقادیر لیبل هر یک از داده ها اشاره دارد. در یادگیری با ناظر هر یک از داده ها مقادیر درست را به همراه داده به الگوریتم می دهیم تا الگوریتم بتواند موارد لازم را یاد بگیرد و در پیش بینی داده های جدید به خوبی عمل کند.
مقدار ¡у به مقادیر لیبل هر یک از داده ها اشاره دارد. در یادگیری با ناظر هر یک از داده ها مقادیر درست را به همراه داده به الگوریتم می دهیم تا الگوریتم بتواند موارد لازم را یاد بگیرد و در پیش بینی داده های جدید به خوبی عمل کند.
مقدار ŷɩ به مقداری اشاره دارد که الگوریتم برای هر یک از داده ها پیش بینی کرده است. هر چه قدر اختلاف این مقادیر با مقادیر اصلی کمتر باشد خطای الگوریتم کمتر است. بنابراین الگوریتم مقادیر داده های جدید را با خطای کمتری پیش بینی می کند.
مقدار loss به مجموع اختلاف مقادیر واقعی و مقادیر پیش بینی شده اشاره دارد. تلاش یک الگوریتم یادگیری این است که بتواند مقدار loss را کاهش دهد.
مشکل رگرسیون خطی این است که ضرایب برآورد شده مدل می تواند بزرگ شود و باعث حساسیت مدل به ورودی ها و احتمالاً ناپایداری الگوریتم شود. این امر به ویژه در مورد مشکلات با چند داده (نمونه) یا نمونه کمتر (n)نسبت به پیش بینی کننده های ورودی (p) یا متغیرها است.
اصطلاحات مهم در مبحث رگرسیون
قبل از ادامه مطلب به بررسی چند اصطلاح مهم در ارتباط با مبحث رگرسیون می پردازیم. از جمله این اصطلاح های رایج در رگرسیون می توان به متغیر مستقل، متغیر وابسته، پارامتر های مربوط به مدل رگرسیون و ضرایب آن، واریانس و بایاس اشاره کرد.
متغیر وابسته: در مدل های رگرسیون متغیری به نام متغیر وابسته (Dependent)تعریف می شود. مقدار این متغیر وابسته به مقادیر متغیر های مستقل است.
متغیر مستقل: متغیر مستقل (independent) مقداری است که به دیگر متغیر ها وابسته نیست و در یک مدل رگرسیونی به عنوان ویژگی از آن یاد می شود.
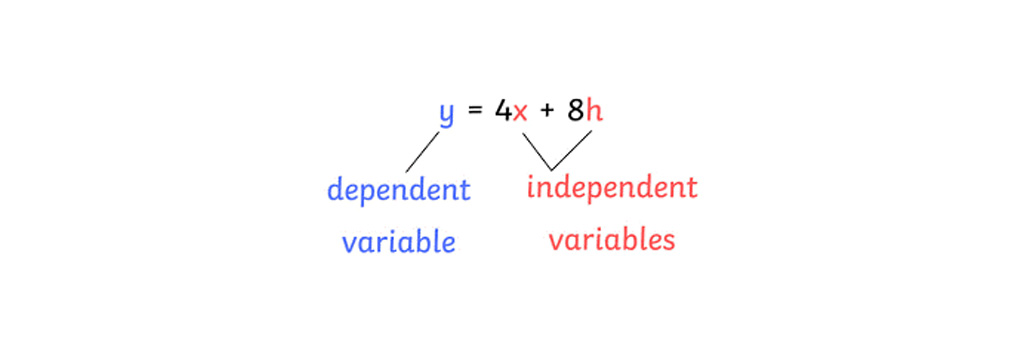
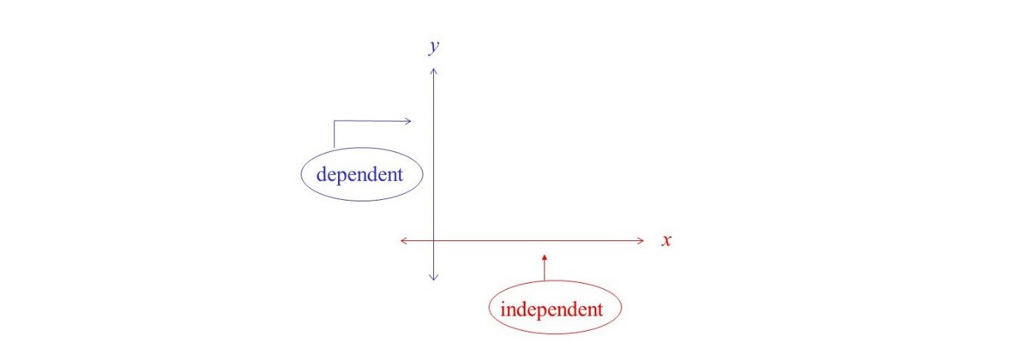
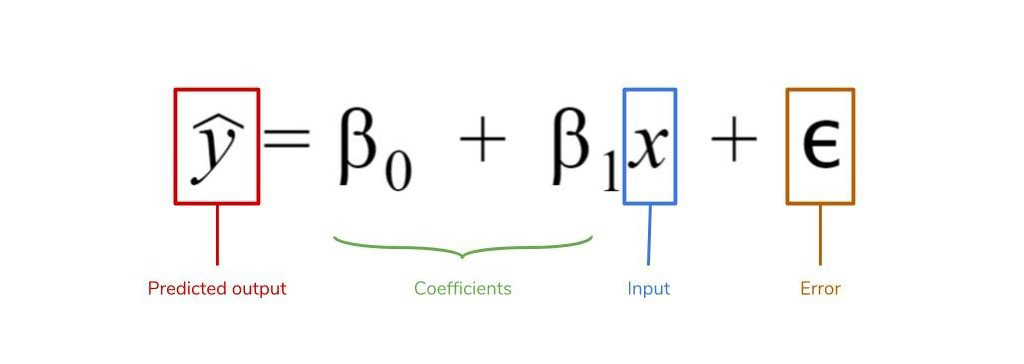
پارامتر مدل رگرسیونی: یک مدل رگرسیونی به مدلی گفته می شود که رابطه بین متغیر مستقل و وابسته را ایجاد می کند. و پارامتر های مدل رگرسیونی به پارامترهایی گفته می شود که برای هر متغیر مستقل باید در نظر گرفته شود تا رابطه ی بین متغیرهای وابسته و مستقل با کمترین میزان خطا برآورده شود. در قسمت زیر βₒ و β1 جز پارامترهای مدل رگرسیونی هستند.
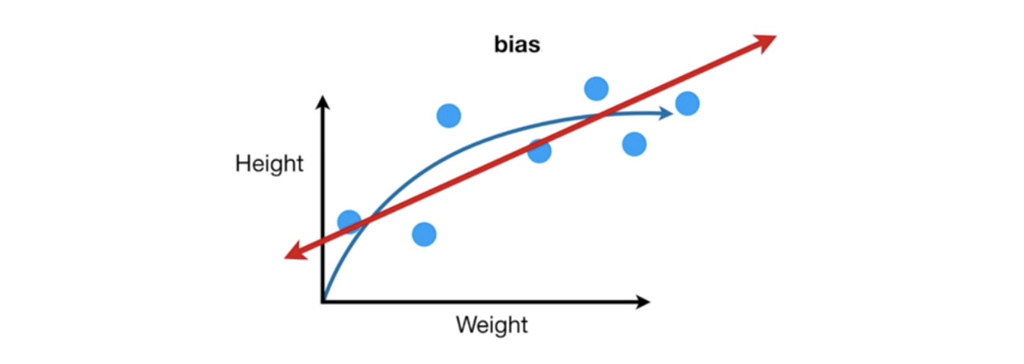
 بایاس (Bias) : بایاس نشان میدهد که پارامترهای تعیین شده برای یک مدل رگرسیونی چه مقدار به اندازه واقعی نزدیک اند یا دور هستند. اگر مقدار بایاس زیاد باشد، نشان دهنده آن است که به طور میانگین پارامترها از مقادیر واقعی این پارامترها دور هستند و در صورتی که مقدار بایاس کم باشد میتوان گفت که به طور میانگین تعیین پارامترها با مقدارهای واقعی بسیار مطابقت دارند. به همین دلیل محاسبه بایاس بسیار مهم است.
بایاس (Bias) : بایاس نشان میدهد که پارامترهای تعیین شده برای یک مدل رگرسیونی چه مقدار به اندازه واقعی نزدیک اند یا دور هستند. اگر مقدار بایاس زیاد باشد، نشان دهنده آن است که به طور میانگین پارامترها از مقادیر واقعی این پارامترها دور هستند و در صورتی که مقدار بایاس کم باشد میتوان گفت که به طور میانگین تعیین پارامترها با مقدارهای واقعی بسیار مطابقت دارند. به همین دلیل محاسبه بایاس بسیار مهم است.
واریانس: برخلاف تعریف آماری، واریانس به معنای گسترش داده ها نیست بلکه نحوه تغییر دقت مدل با توجه به مجموعه داده های مختلف است.
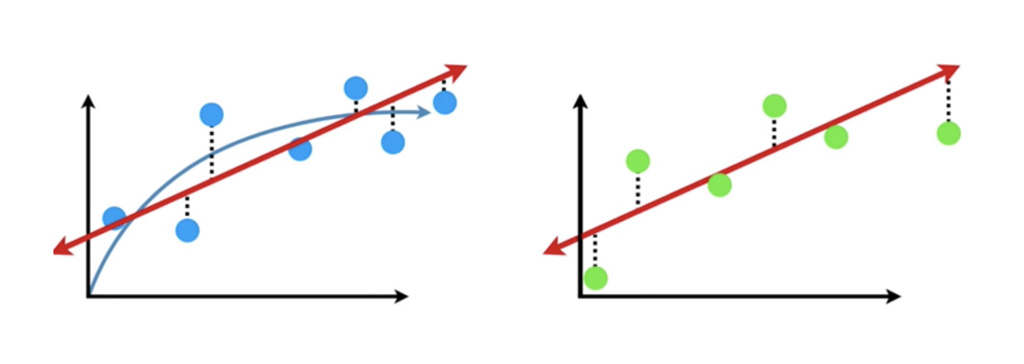
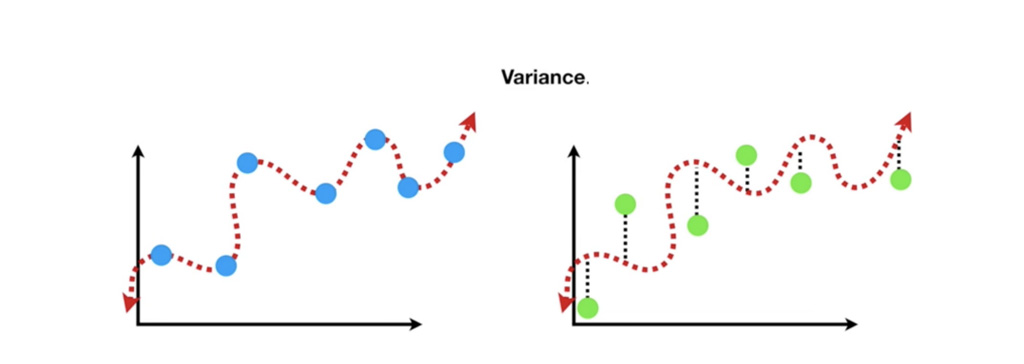 خط ناهموار تصویر بالا در مجموعه داده های دیگر کاملاً متفاوت عمل می کند. بنابراین، می گوییم این مدل واریانس بالایی دارد. از طرف دیگر، خط مستقیم واریانس نسبتاً کمی دارد زیرا مجموع مربع ها برای مجموعه داده های مختلف مشابه است.
خط ناهموار تصویر بالا در مجموعه داده های دیگر کاملاً متفاوت عمل می کند. بنابراین، می گوییم این مدل واریانس بالایی دارد. از طرف دیگر، خط مستقیم واریانس نسبتاً کمی دارد زیرا مجموع مربع ها برای مجموعه داده های مختلف مشابه است.
 معادله مربوط به تعیین خط در رگرسیون خطی به صورت زیر است.
معادله مربوط به تعیین خط در رگرسیون خطی به صورت زیر است.
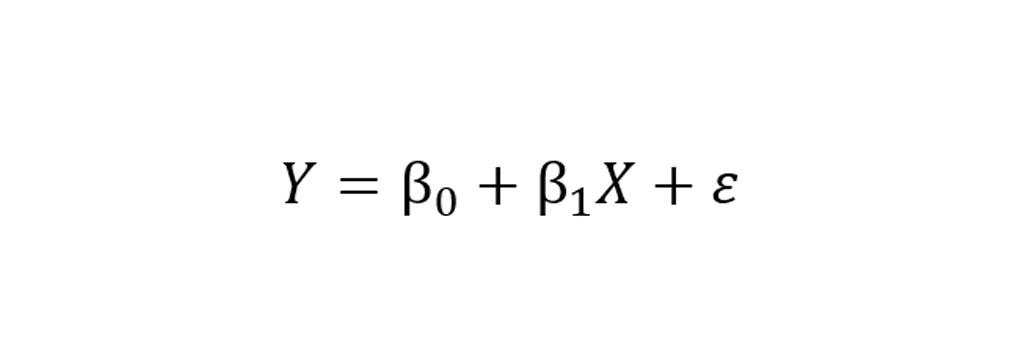 ساختار یک مدل رگرسیون چندگانه به صورت زیر است.
ساختار یک مدل رگرسیون چندگانه به صورت زیر است.
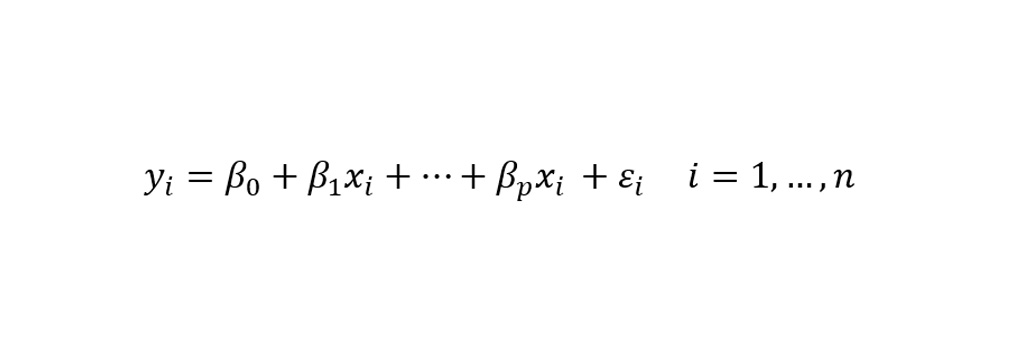 برآورد پارامتر های مدل Ridge Regression در زیر توضیح داده شده است. در این روش تعیین پارامترها به صورت قرار دادن یک شرط بر روی آن تعیین می شود.
برآورد پارامتر های مدل Ridge Regression در زیر توضیح داده شده است. در این روش تعیین پارامترها به صورت قرار دادن یک شرط بر روی آن تعیین می شود.
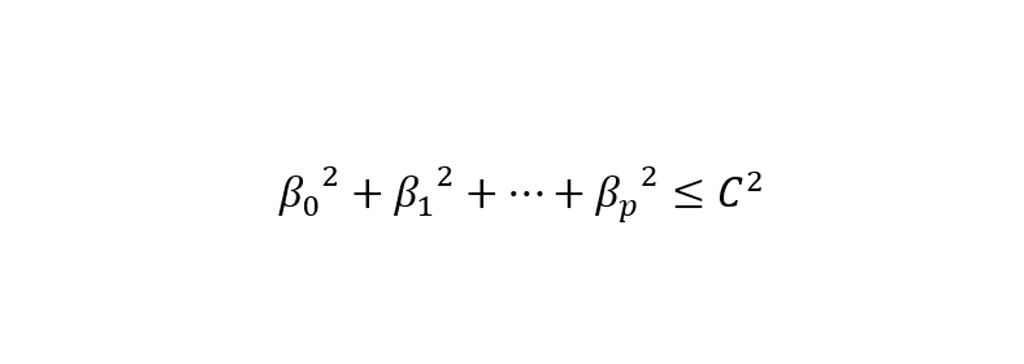 شرط بالا به این صورت است که نشان می دهد مجموع مربعات پارامترها باید از توان دوم پارامتر C کمتر باشد. شرط بالا را می توان به صورت خلاصه به شکل زیر بیان کرد.
شرط بالا به این صورت است که نشان می دهد مجموع مربعات پارامترها باید از توان دوم پارامتر C کمتر باشد. شرط بالا را می توان به صورت خلاصه به شکل زیر بیان کرد.
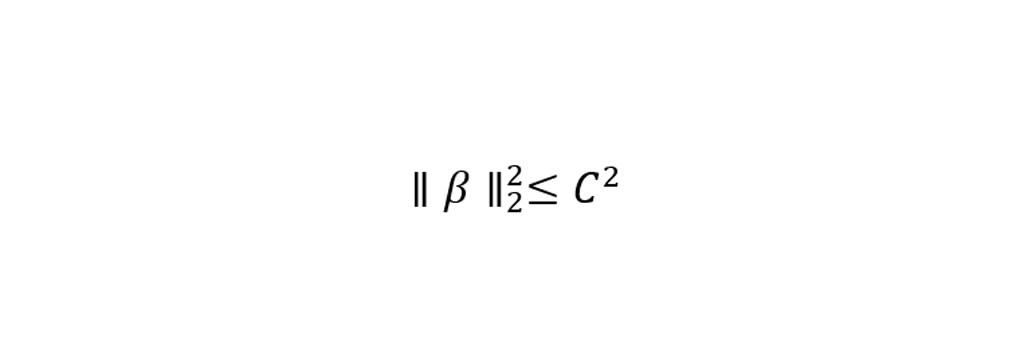 بنابراین مقداری که در این روش باید به صورت کمترین مقدار گیرد شامل معادله زیر می شود.
بنابراین مقداری که در این روش باید به صورت کمترین مقدار گیرد شامل معادله زیر می شود.
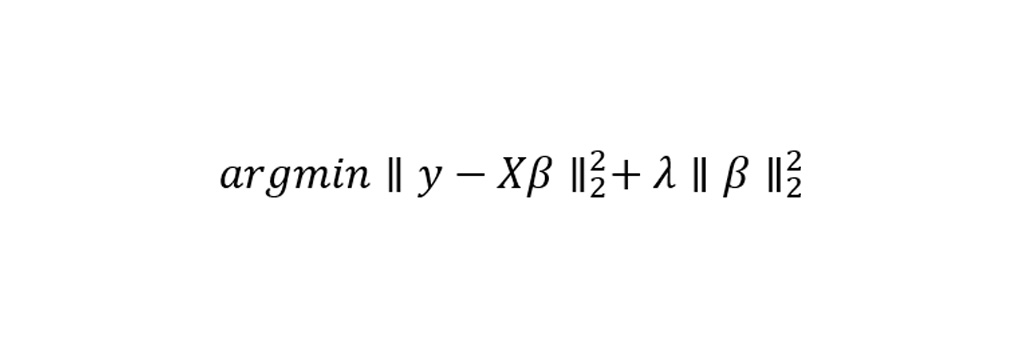 پارامتر λ در این معادله به مقدار پنالتی یا جریمه گفته می شود. در اینجا با افزایش پارامتر ها مقدار λ به ایستایی الگوریتم کمک می کند و از ناپایداری آن جلوگیری می کند.
پارامتر λ در این معادله به مقدار پنالتی یا جریمه گفته می شود. در اینجا با افزایش پارامتر ها مقدار λ به ایستایی الگوریتم کمک می کند و از ناپایداری آن جلوگیری می کند.
مثال رگرسیون Ridge ریج
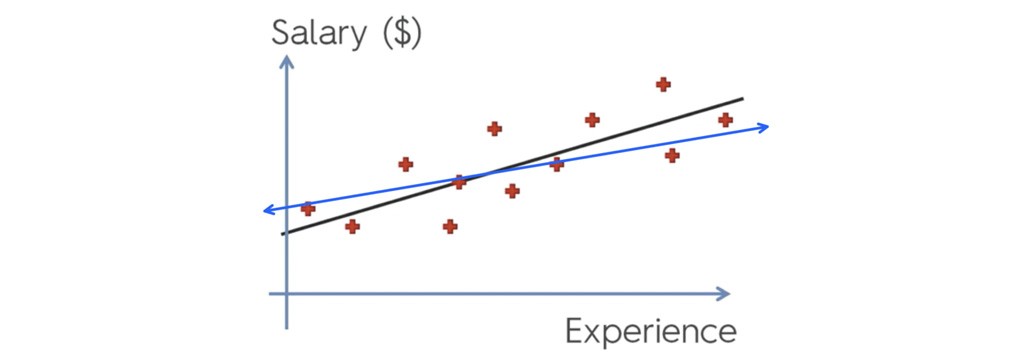
در ادامه به بررسی یک مثال ساده از مثال رگرسیون Ridge ریج می پردازیم.در این مثال قرار است رابطه بین تجربه و حقوق را مورد مطالعه قرار دهیم. در این نمونه تجربه متغیر مستقل است و حقوق متغیر وابسته است.
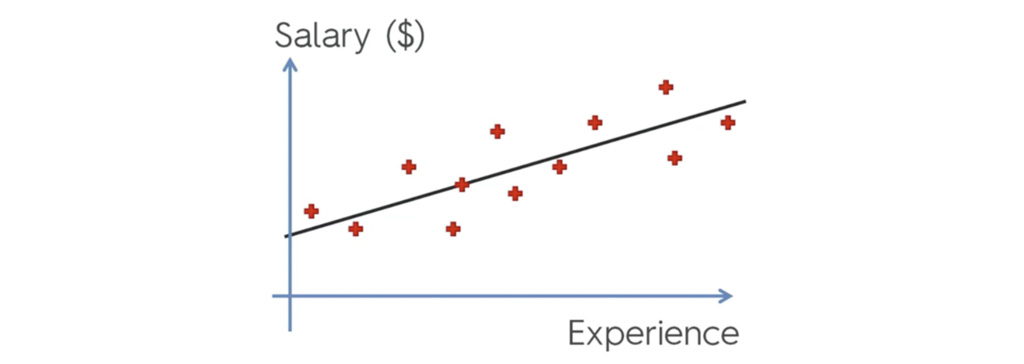
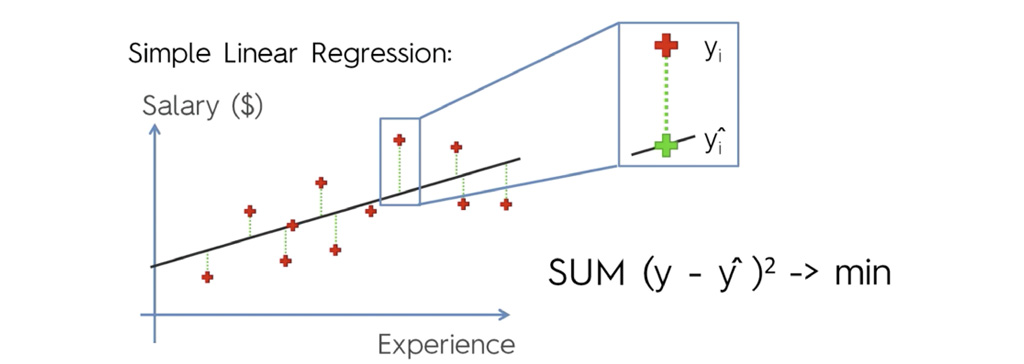
در رگرسیون خطی ساده، با به حداقل رساندن مجموع اختلاف بین مقدار واقعی و مقدار پیش بینی شده مربع، بهترین خط برازش یا خط رگرسیون را تعیین می کنیم.
معادله پنالتی در رگرسیون Ridge ریج به شرح زیر است: در رگرسیون خطی ساده، با به حداقل رساندن مجموع باقی مانده های مربع، بهترین خط برازش را تعیین می کنیم و سپس آن را با مقدار قید رگرسیون Ridge Regression جمع می بندیم. در نمودار زیر خط ابی نتیجه رسم خط توسط Ridge Regression است.
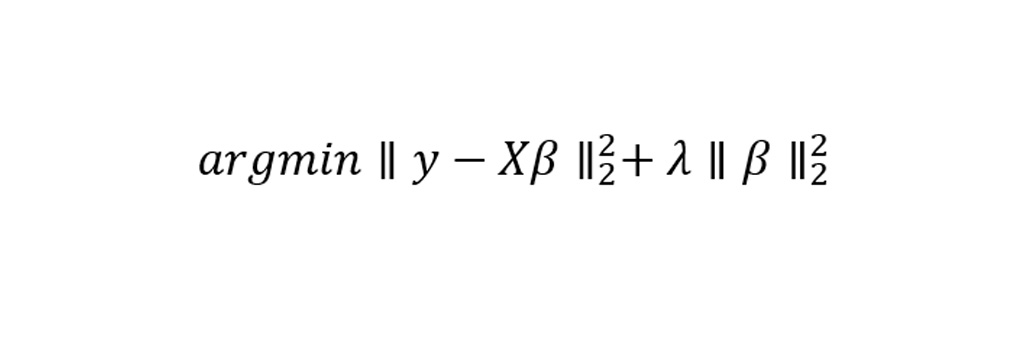
کاربرد رگرسیون Ridge ریج
 کاربرد رگرسیون Ridge ریج
کاربرد رگرسیون Ridge ریجاز کاربرد رگرسیون Ridge ریج میتوان به موارد زیر اشاره کرد:
1- پیش بینی بازار های مالی. در این مسئله ها به دلیل زیاد بودن پارامتر ها بهتر است از افزونه Ridge Regression استفاده شود تا بتوانیم پایداری الگوریتم را حفظ کنیم.
2- پیش بینی بازار مسکن. برای محاسبه قیمت مسکن معمولاً استاندارهای خاصی وجود ندارد استفاده از این الگوریتم کمک می کند تا نظر های شخصی دیگر در تعیین قیمت مسکن دخیل نباشد.
3- پزشکی. بررسی تاثیر دارو و پیش بینی پیشرفت دارو با استفاده از این الگوریتم ها به رحتی امکان پذیر است و می توان با درصد صحت بالا از این الگوریتم استفاده کرد.
4- پیش بینی میزان بارندگی. از این الگوریتم برای بررسیعوامل تاثیر گذار بر بارندگی و عوامل موثر در تخریب محیط زیست بسیار استفاده می شود.
5- پیش بینی پیشرفت تحصیلی. متغیر های مختلفی در پیشرفت یا پس رفت تحصیلی دخیل است. بنابراین می توان با این الگوریتم مطالعات جامعی را روی این مسئله انجام داد.
6- پیش بینی حقوق بر اساس تجربه. تعیین حقوق هر شخص برای اینکه با تجربه و مهارت شخص متناسب باشد بسیار مهم است بنابراین می توان از این روش استفاده کرد تا نظرات شخصی در تعیین حقوق دخیل نباشد.
جمع بندی رگرسیون Ridge ریج
رگرسیون Ridge ریج یک مدل های مهم و پرکاربرد یادگیری ماشین است. این الگوریتم در دسته الگوریتم های یادگیری با ناظر قرار می گیرد و به دنبال یافتن بهترین خط برای پیش بینی مقادیر هدف است. این الگوریتم دارای مدل های توسعه یافته زیادی است. در این مطلب به بررسی Ridge Regression پرداختیم. این افزونه در شرایطی که تعداد پارامتر ها بسیار زیاد است و موجب می شود که الگوریتم رگرسیون خطی از پایداری خارج شود از این اتفاق جلوگیری می کند.
نویسنده: تیم پژوهش راهبرد


دیدگاهتان را بنویسید