رگرسیون لجستیک
سرفصل مطالب
مقدمه بر رگرسیون لجستیک :
رگرسیون لجستیک (Logistic Regression) یکی از پرکاربردترین الگوریتم های حوزه ی یادگیری ماشین است و این الگوریتم در اوایل قرن بیستم در علوم زیستی مورد مطالعه قرار گرفت و پس از آن در بسیاری از کاربردهای علوم اجتماعی مورد استفاده واقع شد. این تکنیک یک روش یادگیری تحت نظارت است و داده ها دارای برچسب مشخص هستند و پروسه ی یادگیری به منظور طبقه بندی بر اساس این داده ها و برچسب های آنها صورت میگیرد. رگرسیون لجستیک هنگامی استفاده میشود که متغیر وابسته (هدف) طبقه ای باشد. تصویر زیر نشان دهنده ی 3 ورودی است که مدل لجستیک رگرسیون با تخصیص وزن قرار است دو دسته خوشحال (Happy) و ناراحت (Sad) را پیش بینی کند.
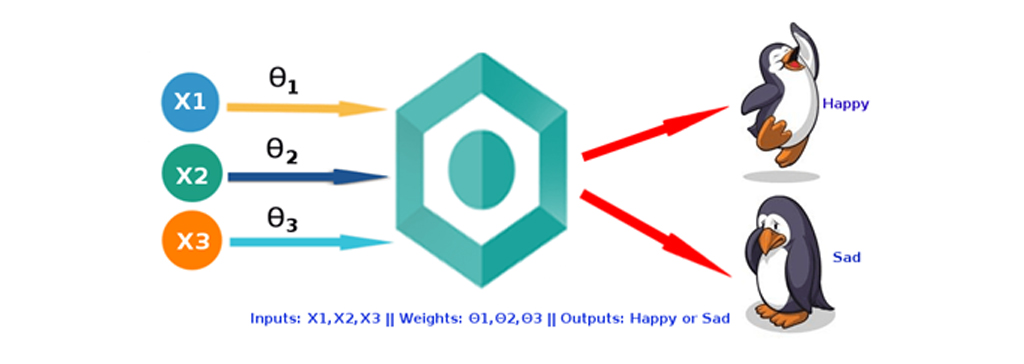
رگرسیون لجستیک (Logistic Regression)
رگرسیون لجستیک (Logistic Regression) یک روش یادگیری ماشین است و یکی از محبوب ترین تکنیک ها برای طبقه بندی داده ها است. در مسئله طبقه بندی هنگامی که باید یک کلاس را از کلاس دیگر تشخیص داد، استفاده میشود. این الگوریتم برای پیش بینی متغیر وابسته طبقه ای با استفاده از یک مجموعه داده شده از متغیرهای مستقل استفاده میشود.
رگرسیون لجستیک به عنوان خروجی یک متغیر وابسته طبقه ای را پیشبینی میکند. بنابراین نتیجه باید یک مقدار طبقه ای یا گسسته باشد. میتواند بله یا خیر، 0 یا 1، درست یا نادرست و غیره باشد.اما به جای دادن مقدار دقیق 0 و 1، مقادير احتمالی بین 0 تا 1 را میدهد. ساده ترین حالت یک طبقه بندی باینری است. این مانند سوالی است که میتوانیم با “بله” یا “نه” پاسخ دهیم. ما فقط دو کلاس داریم: یک کلاس مثبت و یک کلاس منفی. معمولاً یک کلاس مثبت به وجود برخی موجودات اشاره دارد در حالی که کلاس منفی به نبود آن اشاره دارد. در این حالت، ما باید یک مقدار واحد را پیش بینی کنیم که آن احتمال وجود موجودیت. برای انجام این کار، خوب است که ما تابعی داشته باشیم که هر مقدار واقعی را برای تعیین در فاصله بین 0 و 1 ترسیم کند. رگرسیون لجستیک شباهت زیادی به رگرسیون خطی دارد با این تفاوت که نحوه استفاده از آنها متفاوت است.
رگرسیون لجستیک برای شرایطی مفید است که میخواهید بتوانید وجود یا عدم وجود یک مشخصه یا نتیجه را بر اساس مقادیر مجموعه ای از متغیرهای مستقل پیش بینی کنیم. برای برآورد نسبت شانس برای هر یک از متغیرهای مستقل در مدل میتوان از ضرایب رگرسیون لجستیک استفاده کرد. رگرسیون لجستیک در طیف وسیعی از موقعیت های تحقیق نسبت به تجزیه و تحلیل تفکیکی قابل استفاده است.
مثال رگرسیون لجستیک (Logistic Regression)
مثال رگرسیون لجستیک : به طور مثال چه ویژگی هایی سبک زندگی عامل خطر بیماری عروق کرونر قلب هستند؟ با توجه به نمونه ای از بیماران که بر اساس وضعیت سیگار کشیدن، رژیم غذایی، ورزش و مصرف الکل میتوانید با استفاده از چهار متغیر سبک زندگی، مدلی برای پیش بینی وجود یا عدم وجود فاکتور CHD در نمونه ای از بیماران سیگاری بسازید. سپس میتوان از این مدل برای استخراج برآورد نسبت شانس برای هر فاکتور استفاده کرد تا به شما بگوید، به عنوان مثال، احتمال ابتلا به CHD در افراد سیگاری بیشتر از افراد غیر سیگاری است.
یا به طور مثال برای پیشبینی هرزنامه بودن ایمیل (1) یا (0) که در آن ما باید هرزنامه بودن ایمیل را طبقه بندی کنیم. اگر برای این مسئله از رگرسیون خطی استفاده کنیم، نیاز به تنظیم آستانه ای است که براساس آن میتوان طبقه بندی را انجام داد. یا برای تشخیص تومور بدخیم بخواهیم از رگرسیون استفاده کنیم خروجی ما بین (1) یا (0) خواهد بود سناریویی را در نظر بگیرید اگر کلاس واقعی بدخیم است، مقدار پیوسته 0.4 پیش بینی شده و مقدار آستانه 0.5 است، نقطه داده به عنوان غیر بدخیم طبقه بندی میشود.
تفاوت رگرسیون خطی و رگرسیون لجستیک
تفاوت رگرسیون خطی و رگرسیون لجستیک : رگرسیون خطی و رگرسیون لجستیک دو الگوریتم مشهور یادگیری ماشین هستند که دسته ی تکنیکهای یادگیری تحت نظارت قرار میگیرند. از آنجا که هر دو الگوریتم ماهیت نظارت شده دارند، بنابراین این الگوریتم ها از مجموعه داده های دارای برچسب برای پیشبینی استفاده میکنند. اما تفاوت اصلی بین آنها نحوه استفاده از آنهاست. رگرسیون خطی برای حل مشکلات رگرسیون استفاده میشود در حالی که رگرسیون لجستیک برای حل مشکلات طبقه بندی استفاده میشود. در شکل زیر نحوه طبقه بندی در هر دو روش به صورت نمودار مشخص است در ادامه به بررسی این دو روش میپردازیم.
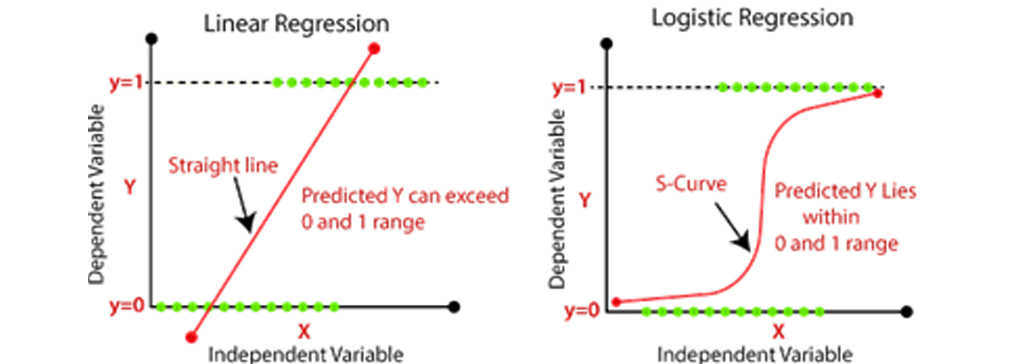
رگرسیون خطی
رگرسیون خطی یکی از ساده ترین الگوریتمهای یادگیری ماشین است که تحت روش یادگیری نظارت شده قرار میگیرد و برای حل مشکلات رگرسیون استفاده میشود. برای پیشبینی متغیر وابسته ی پیوسته از متغیرهای مستقل استفاده میشود. هدف از رگرسیون خطی یافتن بهترین خط برازش است که بتواند خروجی را برای متغیر وابسته ی پیوسته پیشبینی کند.
اگر برای پیشبینی از یک متغیر مستقل منفرد استفاده شود، آنرا رگرسیون خطی ساده مینامند و اگر بیش از دو متغیر مستقل وجود داشته باشد، چنین رگرسیونی را رگرسیون خطی چندگانه مینامند. با یافتن بهترین خط برازش، الگوریتم رابطه بین متغیر وابسته و متغیر مستقل را برقرار میکند. و رابطه باید ماهیت خطی داشته باشد. خروجی برای رگرسیون خطی فقط باید مقادیر پیوسته مانند قیمت، سن، حقوق و غیره باشد. رابطه بین متغیر وابسته و متغیر مستقل را میتوان در تصویر زیر نشان داد:
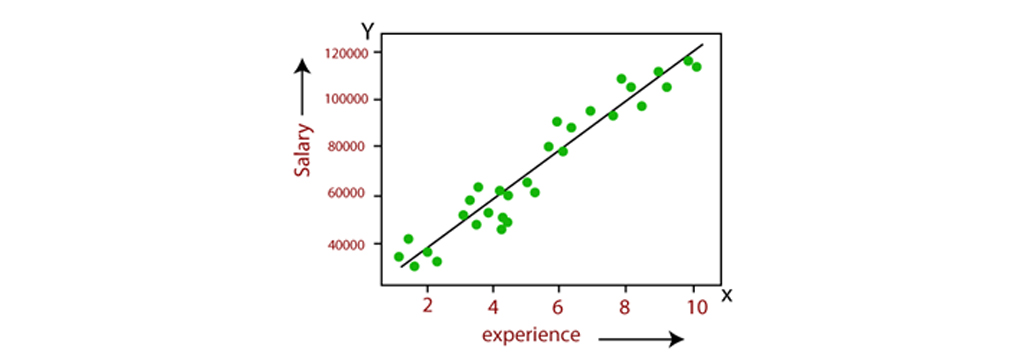
در تصویر بالا متغیر وابسته در محورY(حقوق) و متغیر مستقل در محور x (تجربه) است. خط رگرسیون را میتوان به صورت زیر نوشت:
که در آن ، و ضرایب هستند و ε اصطلاح خطا است.
رگرسیون لجستیک
رگرسیون لجستیک یکی از محبوب ترین الگوریتمهای یادگیری ماشین است که تحت تکنیکهای یادگیری نظارت شده قرار میگیرد. این الگوریتم میتواند برای طبقه بندی و همچنین برای حل مشکلات رگرسیون استفاده شود، اما به طور عمده برای مشکلات طبقه بندی استفاده میشود. رگرسیون لجستیک برای پیشبینی متغیر وابسته طبقه ای با کمک متغیرهای مستقل استفاده میشود. خروجی مسئله رگرسیون لجستیک فقط میتواند بین 0 و 1 باشد. از رگرسیون لجستیک میتوان در مواردی استفاده کرد که احتمال بین دو کلاس وجود دارد مانند اینکه آیا امروز باران میبارد یا نه، صفر یا 1، درست یا نادرست و غیره. رگرسیون لجستیک بر اساس مفهوم برآورد حداکثر احتمال بنا شده است. با توجه به این برآورد، دادههای مشاهده شده باید بسیار محتمل باشند. در رگرسیون لجستیک، ما جمع وزنی ورودیها را از طریق یک تابع فعالسازی که میتواند مقادیر را بین 0 تا 1 ترسیم کند، محاسبه میکنیم. تصویر زیر را در نظر بگیرید:
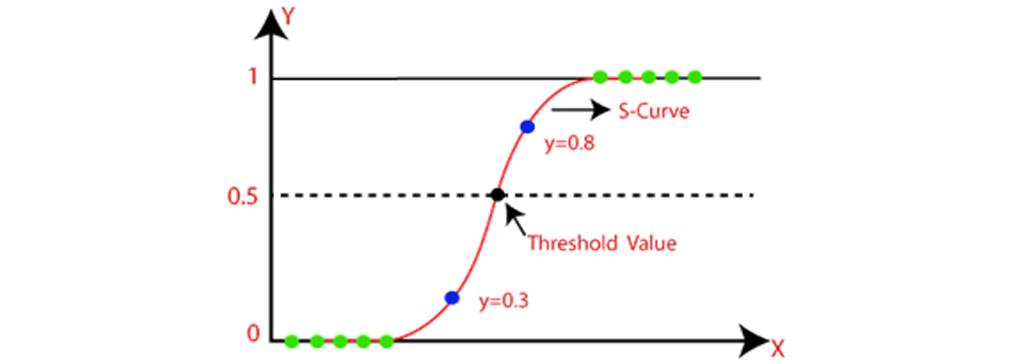
معادله رگرسیون لجستیک
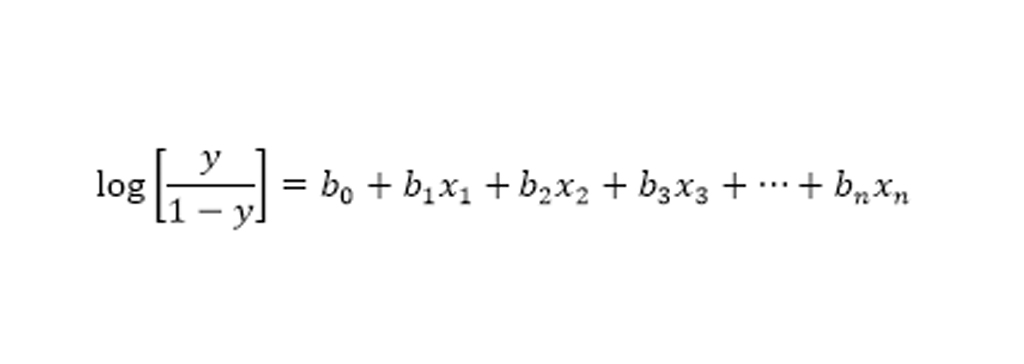
مروری بر عملکرد رگرسیون لجستیک
- رگرسیون لجستیک برای پیش بینی متغیر وابسته طبقه ای با استفاده از یک مجموعه داده شده از متغیرهای مستقل استفاده میشود.
- رگرسیون لجستیک برای حل مسائل طبقه بندی استفاده میشود.
- در رگرسیون لجستیک، ما مقادیر متغیرهای طبقه ای را پیش بینی میکنیم.
- در رگرسیون لجستیک ، منحنی S(S-curve) را پیدا میکنیم که میتواند نمونه ها را توسط آن طبقه بندی کرد.
- برای تخمین دقت از روش تخمین حداکثر احتمال استفاده می شود.
- در رگرسیون لجستیک، وجود رابطه خطی بین متغیر وابسته و مستقل الزامی نیست.
کاربرد رگرسیون لجستیک :
کاربرد رگرسیون لجستیک : رگرسیون لجستیک در زمینه های مختلف از جمله یادگیری ماشین، اکثر رشته های پزشکی و علوم اجتماعی مورد استفاده قرار میگیرد. رگرسیون لجستیک برای محاسبه احتمال وقوع یک رویداد باینری و برای مقابله با مسائل طبقه بندی استفاده میشود. به عنوان مثال، این الگوریتم توان پیشبینی اینکه نامه الکترونیکی ورودی هرزنامه است یا هرزنامه نیست و همچنین پیشبینی میکند که معامله کارت اعتباری جعلی است یا جعلی نیست.
در زمینه پزشکی، ممکن است از رگرسیون لجستیک برای پیشبینی خوش خیم یا بدخیم بودن تومور استفاده شود و میزان آسیب دیدگی که به طور گسترده برای پیش بینی مرگ و میر در بیماران مصدوم مورد استفاده قرار می گیرد و رگرسیون لجستیک برای پیش بینی خطر ابتلا به یک بیماری خاص به عنوان مثال دیابت، بر اساس ویژگی های مشاهده شده بیمار (سن، جنس، شاخص توده بدنی، نتایج آزمایش های مختلف خون) مورد استفاده قرار گیرد.
در بازاریابی، ممکن است برای پیشبینی اینکه آیا کاربر معین (یا گروهی از کاربران) کالای خاصی را خریداری میکند یا خیر، استفاده شود. یک شرکت آموزش آنلاین ممکن است با استفاده از رگرسیون لجستیک پیشبینی کند آیا دانشجو دوره خود را به موقع به پایان میرساند یا خیر.
رگرسیون لجستیک در علوم سیاسی هم کاربرد دارد. به عنوان مثال این مدل می تواند بر روی پیش بینی اینکه رای دهنده ی خاص در رای گیری شرکت میکند و رای دهد، بر اساس سن، درآمد، جنس، نژاد، آرا در انتخابات قبلی و غیره کارکند؛
همانطور که میبینید، از رگرسیون لجستیک برای پیشبینی احتمال انواع نتایج “بله” یا “نه” استفاده میشود. با پیشبینی چنین نتایجی، رگرسیون لجستیک به تحلیلگران داده (و شرکتهایی که در آنها کار میکنند) کمک میکند تا آگاهانه تصمیم بگیرند. در طرح کلی موارد، این امر به حداقل رساندن خطر ضرر و بهینه سازی هزینهها برای به حداکثر رساندن سود کمک میکند.
مزایای رگرسیون لجستیک
مزایای رگرسیون لجستیک : الگوریتم رگرسیون لجستیک یک تکنیک بسیار پرکاربرد و کارآمد است، به منابع محاسباتی زیادی احتیاج ندارد، بسیار قابل تفسير است، خروجی احتمالات پیش بینی شده را به خوبی کالیبره میکند و رگرسیون یک خط مبنای خوب است که می توان از آن برای اندازه گیری عملکرد الگوریتمهای پیچیده تر استفاده کرد.
مزیت دیگر رگرسیون لجستیک این است که اجرای آن بسیار آسان است و آموزش آن بسیار کارآمد است. مانند رگرسیون خطی، رگرسیون لجستیک هنگامی که ویژگیهایی را که با متغیر خروجی ارتباط ندارند و همچنین ویژگیهایی که بسیار شبیه به یکدیگر هستند را حذف می کنید، بهتر عمل میکند. بنابراین مهندسی ویژگی نقش مهمی در عملکرد رگرسیون لجستیک و خطی دارد.
در آخر، مهمترین مزایای رگرسیون لجستیک نسبت به شبکه های عصبی شفافیت است. شبکه های عصبی به عنوان یک جعبه سیاه کار میکنند (شما هرگز نمیدانید چرا در این لحظه الگوریتم این تصمیم را میگیرد). بسیاری از صنایع با نظارت بسیار زیاد وجود دارند که این روش (شبکه ی عصبی) قابل قبول نیست. در مقابل، رگرسیون لجستیک را میتوان “جعبه سفید” نامید. شما همیشه میدانید که چرا درخواست وام را رد شد یا چرا تشخیص بیماری بدخیم یا خوشخیم به نظر میرسد.
معایب رگرسیون لجستیک
معایب رگرسیون لجستیک : یکی از ضعف های این الگوریتم این است که حل مشکلات غیر خطی را با رگرسیون لجستیک امکان پذیر نیست زیرا سطح تصمیم گیری آن خطی است.
یکی دیگر از معایب رگرسیون لجستیک این است که در این مدل باید تمامی متغیرهای مهم مستقل را شناسایی کرد. از آنجا که نتیجه آن گسسته است، رگرسیون لجستیک فقط می تواند یک نتیجه طبقه بندی شده را پیش بینی کند.
یکی دیگر از معایب رگرسیون لجستیک این است که اگر اندازه نمونه خیلی کوچک باشد ممکن است رگرسیون لجستیک دقیق نباشد. اگر اندازه نمونه در سمت کوچک باشد، مدل تولید شده توسط رگرسیون لجستیک براساس تعداد کمتری از مشاهدات واقعی ایجاد شده است. این میتواند باعث بیش برازش شود.
در آمار، بیش برازش یا overfitting یک خطای مدل سازی است که هنگامی رخ میدهد که مدل به دلیل کمبود اطلاعات آموزش، با مجموعه محدودی از داده ها اموزش دیده باشد یا به عبارت دیگر، داده های ورودی کافی برای یافتن الگوها در مدل وجود ندارد. در این حالت، مدل قادر به پیش بینی دقیق نتایج یک مجموعه داده جدید نیست.
نتیجه گیری رگرسیون لجستیک
رگرسیون لجستیک (Logistic Regression) یکی از روشهای کلاسیک یادگیری ماشین است. این یک مبنای یادگیری ماشین همراه با رگرسیون خطی، خوشه بندی میانگین k ، تجزیه و تحلیل مولفه های اصلی و برخی دیگر است. رگرسیون لجستیک یک طبقه بندی کننده یادگیری ماشین تحت نظارت است که ویژگیهای با ارزش واقعی از ورودی را استخراج میکند، هر یک را در یک وزن ضرب میکند، آنها را جمع میکند و مجموع را از طریق یک تابع سیگموئید عبور میدهد تا یک احتمال ایجاد کند.
و همچنین رگرسیون لجستیک نیز یکی از مفیدترین ابزارهای تحلیلی است، زیرا دارای آن است که توانایی مطالعه شفاف اهمیت ویژگیها را داراست. به دست آوردن بهترین نتایج از رگرسیون لجستیک بستگی به درک زمان مفید بودن این روش تجزیه و تحلیل دارد، و اینکه چه زمانی ممکن است بهترین سناریو نباشد. به طور كلی، قوانین كاملاً باید با احتیاط استفاده شود که مدل دچار خطاهای اماری نشود. متخصصان تجزیه و تحلیل و علوم داده برای ایجاد نتایجی که میتوانند مزایای خوبی داشته باشند میتوانند از این الگوریتم استفاده کنند.
اگر میخواهید هوش مصنوعی به زبان ساده را بدانید مقاله لینک داده شده را حتما مطالعه کنید.
نویسنده: تیم پژوهش راهبرد
منابع
javatpoint.com
stat.cmu.edu





دیدگاهتان را بنویسید