رگرسیون چند جمله ای Polynomial Regression
سرفصل مطالب
مقدمه ای بر رگرسیون چند جمله ای Polynomial Regression
تجزیه و تحلیل رگرسیون نوعی از مدل سازی پیش بینی است که رابطه بین یک متغیر وابسته و مستقل را بررسی می کند. تعریف فوق یک تعریف رسمی است، به عبارت ساده می توان رگرسیون را اینگونه تعریف کرد، “استفاده از رابطه بین متغیرها برای یافتن بهترین خط مناسب یا معادله رگرسیون که می تواند برای پیش بینی استفاده شود”. رگرسیون چند جمله ای شکلی از تحلیل رگرسیون است که در آن رابطه بین متغیرهای مستقل و متغیرهای وابسته در چند جمله ای درجه nام مدل شده است. رگرسیون چند جمله ای یک مورد خاص از رگرسیون خطی است که در آن معادله چند جمله ای را بر روی داده ها با رابطه منحنی بین متغیرهای وابسته و مستقل قرار می دهیم.

کاربرد رگرسیون چند جمله ای
برای درک نیاز به رگرسیون چند جمله ای، ابتدا تعدادی مجموعه داده تصادفی ایجاد کنیم. به طور مثال داده ها در یک جدول رسم شده اند.
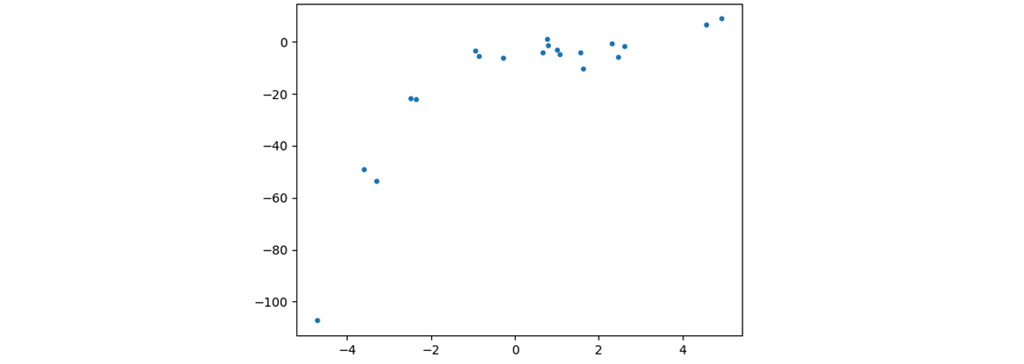
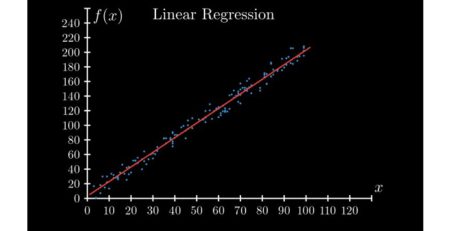
بیایید یک مدل رگرسیون خطی را برای این مجموعه داده اعمال کنیم. از رگرسیون خطی این انتظار را داریم که بتواند داده ها را به خوبی از یک دیگر جدا کند. داده های تولید شده دارای یک انحنا در توزیع خود هستند. در شکل زیر نتیجه اعمال رگرسیون را مشاهده می کنید.
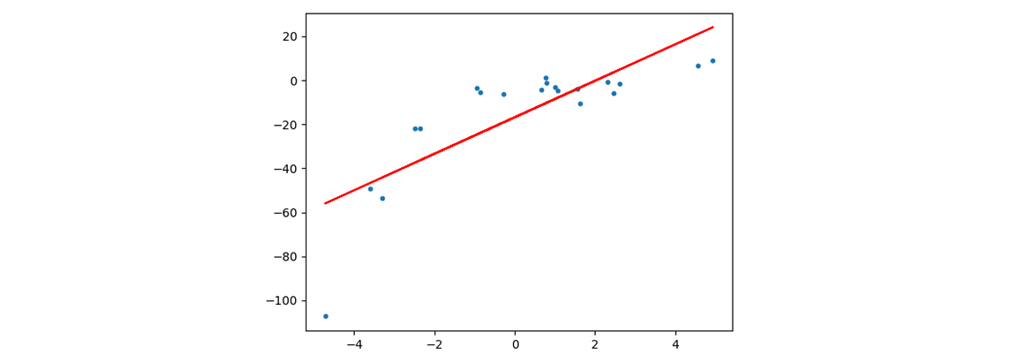
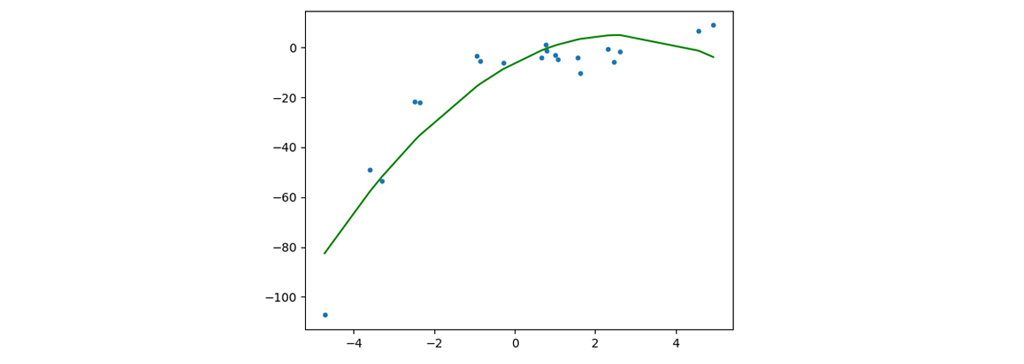
در این نمودار مشاهده می کنیم که خط مستقیم قادر به ثبت الگوهای داده نیست. این نمونه ای از عدم تناسب است. مدل خود را می سازیم و متوجه می شویم که عملکرد بسیار بدی دارد، ما بین مقدار واقعی و بهترین خط مناسب، که مدل ایجاد کرده، اختلاف می بینیم. به نظر می رسد که مقدار واقعی دارای یک نوع منحنی در نمودار است و خط ما در پیش بینی و تقسیم بندی داده ها ناتوان بوده است. در این گونه موارد رگرسیون چند جمله ای برای مدل سازی استفاده می شود، بهترین خط مناسب را که از الگوی (منحنی) داده ها پیروی می کند، پیش بینی کرده، همانطور که در عکس زیر نشان داده شده است.
معادله رگرسیون خطی
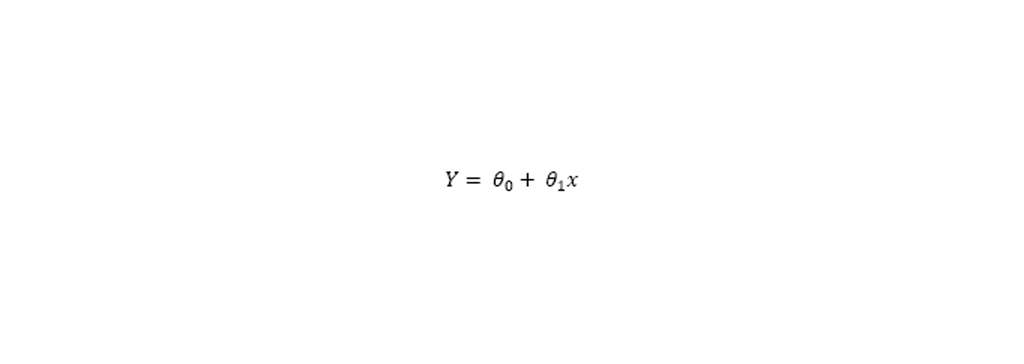
این معادله تبدیل می شود به رگرسیون چند جمله ای:
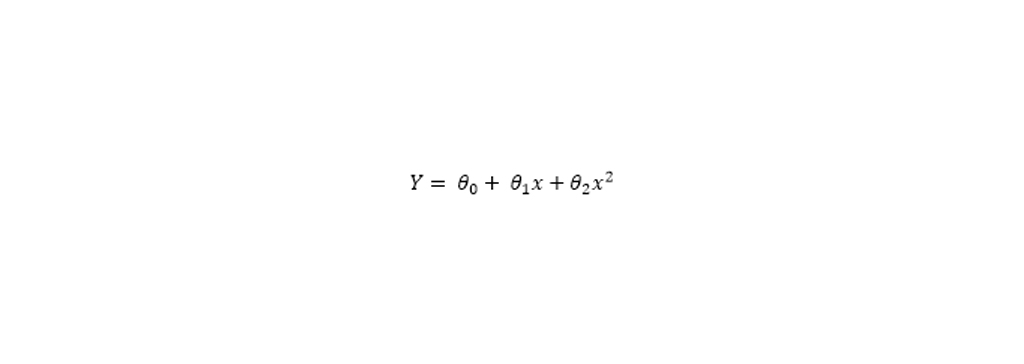
برازش یک مدل رگرسیون خطی بر روی ویژگی های تغییر یافته نمودار بالا را نشان می دهد.
برای غلبه بر عدم تناسب، باید پیچیدگی مدل را افزایش دهیم. برای ایجاد معادله مرتبه بالاتر می توانیم ویژگی های اصلی را به عنوان ویژگی های جدید اضافه کنیم. از نمودار کاملاً مشخص است که منحنی درجه دوم می تواند داده ها را بهتر از رگرسیون خطی دسته بندی کند.
رگرسیون چند جمله ای نیازی به رابطه خطی بین متغیرهای مستقل و وابسته در مجموعه داده ها ندارد، این نیز یکی از تفاوت های اصلی بین رگرسیون خطی و چند جمله ای است. رگرسیون چند جمله ای عموماً زمانی مورد استفاده قرار می گیرد که نقاط داده توسط مدل رگرسیون خطی ضبط نشده و رگرسیون خطی در توصیف بهترین نتیجه به وضوح ناموفق باشد. همانطور که درجه را در مدل افزایش می دهیم، عملکرد مدل را افزایش می دهد. با این حال، افزایش درجه مدل همچنین خطر تطابق بیش از حد و عدم تناسب داده ها را افزایش می دهد.
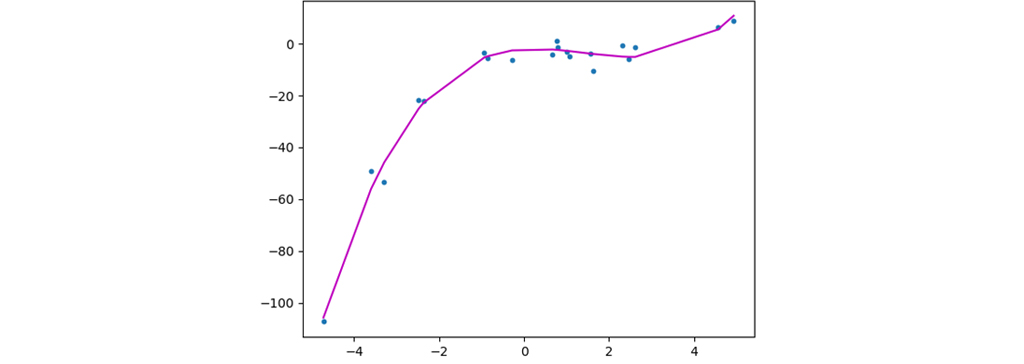
اکنون برای اینکه بتوانیم مدل بهتری بسازیم سعی می کنیم که یک مدل درجه 3 را برای این داده ها امتحان کنیم. هرچه پیچیدگی داده ها بیشتر شود، می توانیم پیچیدگی مدل را نیز افزایش دهیم تا کیفیت مدل بالاتر رود. شکل زیر مدل رگرسیون چندجمله ای است که بر روی این داده ها آموزش دیده است. همان طور که مشاهده می کنید این نمودار از دو نمودار قبلی بهتر توانسته داده ها را یاد بگیرد و در پیش بینی موفق تر بوده است.
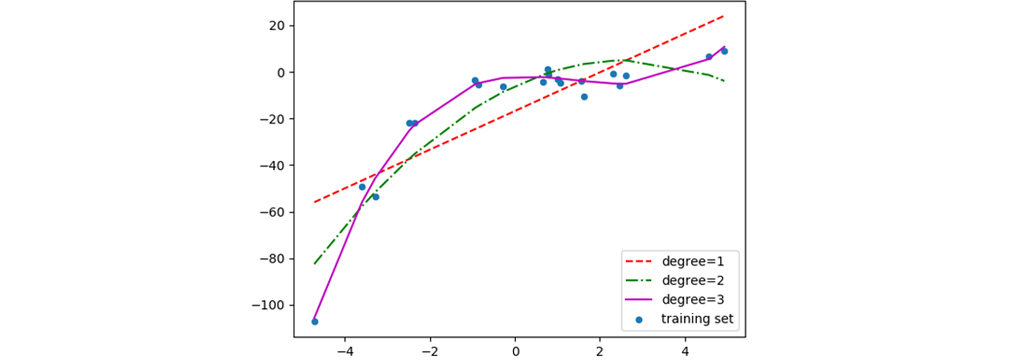
برای درک بهتر این رگرسیون در زیر مقایسه منحنی های رگرسیون خطی، رگرسیون درجه دوم و رگرسیون درجه سوم بر روی مجموعه داده ها آمده است. با یک نگاه کاملاً می توان تفاوت مدل ها را متوجه شد و فهمید که رگرسیون خطی در این نوع از داده بسیار ضعیف عمل کرده و رگرسیون درجه سه از دیگر مدل ها بهتر عمل کرده است.
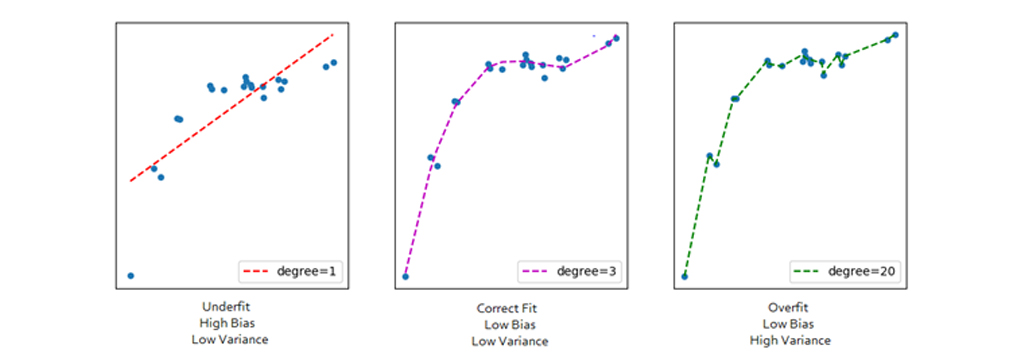
با افزایش پیچیدگی داده ما نمی توانیم به صورت صعودی پیچیدگی مدل را افزایش دهیم و به دنبال این باشیم که مدل پیچیده تر داده های ما را بهتر یاد بگیرد. به طور مثال اگر درجه معادله را به 20 افزایش دهیم، می بینیم که منحنی از نقاط داده بیشتری عبور می کند. در زیر مقایسه منحنی ها برای درجه 3 و 20 آمده است.

برای معادله با درجه 20، مدل همچنین نویز (داده هایی که به اشتباه ثبت شده اند) را در داده ها ضبط می کند. این نمونه ای از برازش بیش از حد (Overfitting) است. اگرچه این مدل از اکثر داده ها عبور می کند، اما نمی تواند برای داده های جدید پیش بینی کننده خوبی باشد. برای جلوگیری از برازش بیش از حد، می توانیم نمونه های آموزشی بیشتری اضافه کنیم تا الگوریتم نویز سیستم را یاد نگیرد و تعمیم بیشتری پیدا کند. برای درجه = 20، مدل همچنین نویز را در داده ها ضبط می کند. اینکه چگونه یک مدل بهینه را انتخاب کنیم بسیار مسئله ی مهمی است. برای یافتن بهترین مدل، ما باید تعادل بایاس در مقابل واریانس را درک کنیم.
واریانس:
واریانس به خطای ناشی از مدل پیچیده ای که سعی در تطبیق داده ها دارد، اشاره دارد. واریانس بالا به این معنی است که مدل از بیشتر نقاط داده عبور می کند و منجر به برازش بیش از حد داده ها می شود.
بایاس:
بایاس به خطای ناشی از مفروضات ساده مدل در برازش داده ها اشاره دارد. بایاس زیاد بدین معناست که مدل قادر به ثبت الگوهای داده نیست و این منجر به عدم تناسب می شود.
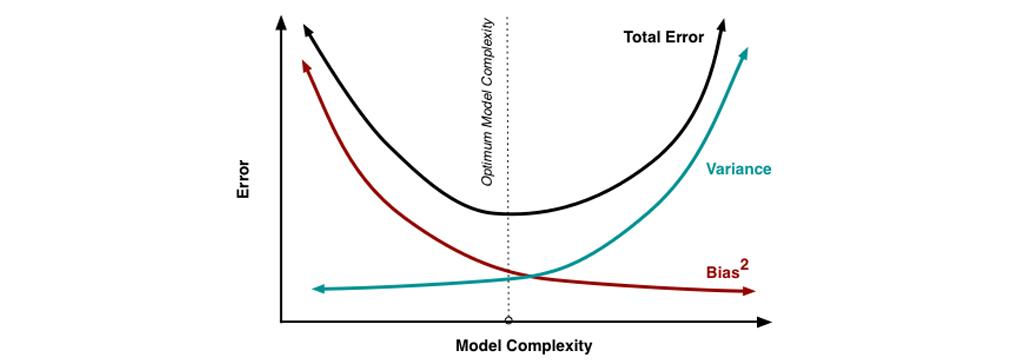
تصویر زیر خلاصه ای از یادگیری مدل ها است.
از تصویر زیر می توانیم مشاهده کنیم که با افزایش پیچیدگی مدل، بایاس کاهش می یابد و واریانس افزایش می یابد و برعکس. در حالت ایده آل، یک مدل یادگیری ماشین باید دارای واریانس کم و بایاس کم باشد. اما عملاً داشتن هر دو غیرممکن است. بنابراین برای دستیابی به یک مدل خوب که هم در داده های آموزش و هم در داده های جدید عملکرد خوبی داشته باشد، یک مبادله انجام می شود.
چگونه می توان درجه مناسب معادله را پیدا کرد؟
به منظور یافتن درجه مناسب برای مدل برای جلوگیری از برازش بیش از حد (Over-fitting) و یا عدم برازش (under-fitting)، می توانیم از موارد زیر استفاده کنیم:
Select forward: این روش درجه را افزایش می دهد تا جایی که برای تعریف بهترین مدل ممکن به اندازه کافی قابل توجه باشد.
Select backward: این روش درجه را تا زمانی که به اندازه کافی قابل توجه باشد تا بهترین مدل ممکن را مشخص کند، کاهش می دهد.
تابع هزینه رگرسیون چند جمله ای
تابع هزینه رگرسیون چند جمله ای : تابع هزینه یک تابع است که عملکرد یک مدل یادگیری ماشین را برای داده های دیتا ست اندازه گیری می کند. تابع هزینه اساساً محاسبه خطا بین مقادیر پیش بینی شده و مقادیر مورد انتظار است و آن را در قالب یک عدد واقعی واحد ارائه می دهد. تابع هزینه میانگین خطای n نمونه در بین داده ها است.
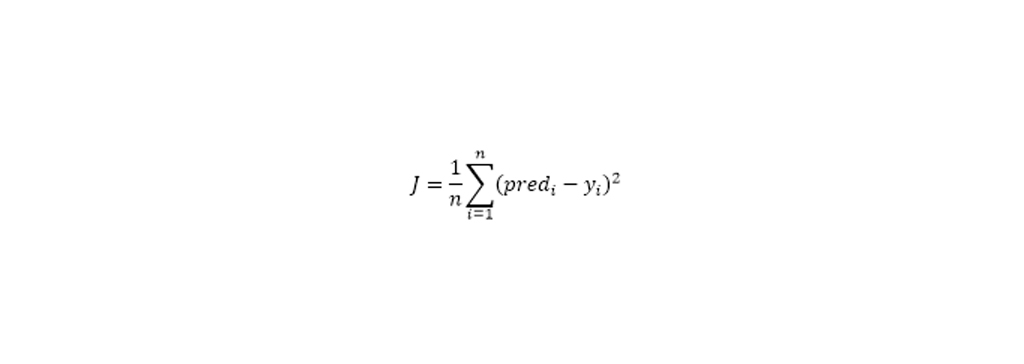
تابع هزینه رگرسیون چند جمله ای را می توان خطای میانگین مربع نیز در نظر گرفت، با این حال تغییر کمی در معادله ایجاد می شود.
مزایای استفاده از رگرسیون چند جمله ای
چند جمله ای بهترین تقریب رابطه بین متغیر وابسته و مستقل را ارائه می دهد و طیف وسیعی از عملکردها را می توان با آن پوشش داد. رگرسیون چند جمله ای اساساً با طیف گسترده ای از انحنای موجود در داده ها مطابقت دارد.
معایب استفاده از رگرسیون چند جمله ای
وجود یک یا دو داده پرت در بین داده ها می تواند نتایج تجزیه و تحلیل غیر خطی را به طور جدی تحت تأثیر قرار دهد. رگرسیون خطی نسبت به داده های دور بسیار حساس است. علاوه بر این، متأسفانه ابزارهای تأیید مدل کمتری برای تشخیص نقاط دور در رگرسیون غیر خطی نسبت به رگرسیون خطی وجود دارد.
خلاصه ای از رگرسیون چندجمله ای
این یک نوع رگرسیون غیر خطی است که رابطه متغیر مستقل و وابسته را هنگامی که متغیر وابسته به متغیر مستقل درجه nام مربوط می شود به ما می گوید. بهترین خط تناسب با درجه معادله رگرسیون چند جمله ای تعیین می شود. مدل حاصل از رگرسیون چند جمله ای تحت تأثیر عوامل بیرونی قرار می گیرد، بنابراین همیشه بهتر است قبل از اعمال الگوریتم در مجموعه داده، نقاط دور را تشخیص دهیم. ماهیت منحنی را می توان با استفاده از یک نمودار پراکندگی ساده مورد مطالعه یا تجسم قرار داد، که به شما ایده بهتری در مورد رابطه خطی یا غیر خطی بین متغیرها می دهد و بر این اساس تصمیم گیری می کنید و مدل بهتر را انتخاب خواهید کرد.
کاربرد رگرسیون چند جمله ای
کاربرد رگرسیون چند جمله ای ، استفاده از رگرسیون چند جمله ای در بسیاری از مطالعات تجربی برای تولید پیش بینی نتیجه به کار می رود. به این دلیل که این یک رابطه تعریف شده عالی بین متغیرهای مستقل و وابسته را ارائه می دهد.
- پیش بینی شاخص بورس و بازار سهام
- پیش بینی وقوع زلزله
- پیش بینی بهبود کیفیت در خطوط تولید و به طور کلی بررسی خطوط کنترل کیفیت
- بررسی رضایت مشتری(از لحاظ کیفیت، قیمت و بسته بندی)
- بررسی قیمت مسکن
- پیش بینی میزان پیشرفت بیماری و تاثیر دارو روی یک بیماری
- بررسی افزایش بیماری های مختلف در هر جمعیت
تفاوت Overfitting و Underfitting
تفاوت Overfitting و Underfitting : در متن اشاره ای گذرا به اصطلاح بیش برازش(Over-fitting) و برازش کم تر از حد (under-fitting) شد. بهتر است این دو اصطلاح مهم در علم یادگیری ماشین را به صورت مختصر بررسی کنیم. این دو مورد از شایع ترین دلایل عدم دقت مدل های یادگیری ماشین هستند. تناسب مدل را می توان با نگاهی به خطای پیش بینی در داده های آموزش و آزمون پیش بینی کرد.
در یک مدل under-fitting منجر به خطاهای پیش بینی بالا برای داده های آموزشی و آزمون می شود. در یک مدل Over-fitting دارای خطای پیش بینی بسیار کم در مورد داده های آموزش می شود، اما یک خطای پیش بینی بسیار بالا در داده های آزمون دارد. هر دو مدل دارای دقت ضعیفی هستند.
همان طور که در شکل زیر مشاهده می کنید یک مدل دارای Over-fitting تمامی داده ها را حفظ کرده بنابراین داده های جدیدی که وارد سیستم شوند را به خوبی درک نخواهد کرد. مدلی که دارای under-fitting است منحنی پیش بینی خود را با اختلاف زیاد رسم کرده است و خیلی از داده فاصله دارد. مدل Optimal منحنی متناسب با داده ها رسم می کند. این منحنی حداقل خطا را دارد.
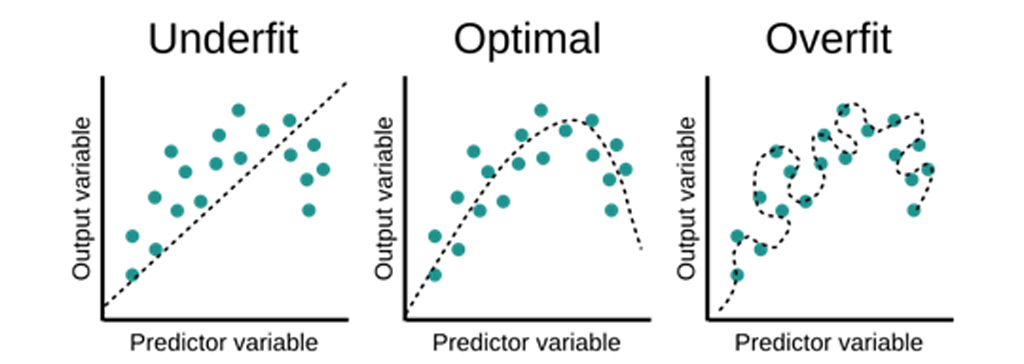
یک مدل under-fitting نمی تواند به طور قابل توجهی رابطه بین مقادیر ورودی و متغیرهای هدف را درک کند. این ممکن است زمانی اتفاق بیفتد که مدل خیلی ساده باشد (یعنی ویژگی های ورودی به اندازه کافی توضیح دهنده هدف نباشند). یک مدل Over-fitting مجموعه داده هایی را که دیده است بیش از حد حفظ کرده است و نمی تواند یادگیری را به مجموعه داده های جدید تعمیم دهد. به همین دلیل است که یک مدل Over-fitting دقت آزمایش بسیار ضعیفی را نشان می دهد. دقت تست ضعیف ممکن است زمانی رخ دهد که مدل بسیار پیچیده باشد، یعنی ترکیب ویژگی های ورودی تعداد زیادی باشد و بر انعطاف پذیری مدل تأثیر می گذارد.
دیتاست در هنگام طراحی مدل به دو قسمت تقسیم می شود به طور معمول 70 درصد داده ها را برای آموزش استفاده می کنند و به این داده ها داده ی آموزش می گویند. 30 درصد باقی مانده داده را داده تست می گویند و بعد از انجام آموزش دقت مدل را با استفاده از داده های تست می سنجند.
جمع بندی رگرسیون چند جمله ای
رگرسیون چند جمله ای روشی پارامتری برای برازش منحنی روی داده ها می باشد که در آن ارتباط بین متغیر پاسخ و متغیرهای مستقل به صورت چند جمله ای برآورد می شود. در بسیاری از مواقع در مورد نحوه ارتباط بین متغیرها اطلاع زیادی در دست نیست. در این صورت بهتر است به جای مفروض داشتن یک الگوی پارامتری خاص (مانندچند جمله ای) برای داده ها از روشی استفاده شود که داده ها ماهیت روند خود را بهتر نشان دهند. برای نمونه های با حجم بزرگ رگرسیون چند جمله ای روشی آسان تر و سریع تر است.
نویسنده: تیم پژوهش راهبرد
منابع
towardsdatascience.com


دیدگاه (4)
عالی و کامل
سپاسگزاریم.
خیلی عالی توضیح داده شده .
سپاسگزاریم.