الگوریتم دسته بندی بیز ساده Naive Bayes
سرفصل مطالب
مقدمه ای بر الگوریتم دسته بندی بیز ساده Naive Bayes :
الگوریتم دسته بندی بیز ساده Naive Bayes : عدم اطمینان و احتمال در پدیده های مختلف منجر به این شده که یادگیری ماشین در هوش مصنوعی باید با داده هایی کار کند که در بسیاری از موارد بزرگ است اما با در نظر گرفتن داده های از دست رفته و مدیریت این گونه داده ها خواهد بود. دقیقاً مانند انسانها، کامپیوتر نیز باید ریسک کند و به آینده ای که قطعی نیست فکر کند.
تحمل عدم اطمینان برای انسان سخت است؛ اما در یادگیری ماشین ، الگوریتم های خاصی وجود دارد که به شما کمک میکند تا راه حل این محدودیت را پیدا کنید. الگوریتم یادگیری ماشین دسته بندی بیز ساده یا Naive Bayes یکی از ابزارهای مقابله با عدم اطمینان با کمک روش های احتمالی است. احتمال، زمینه ای از ریاضیات است که ما را قادر میسازد تا بتوانیم با وجود عدم قطعیت استدلال کنیم و احتمال برخی نتایج یا رویدادها را ارزیابی کنیم.

Naive bayes در یادگیری ماشین
Naive bayes در یادگیری ماشین : این یک روش طبقه بندی بر اساس قضیه بیز با فرض استقلال در بین پیشبینی کننده ها است. به زبان ساده، یک طبقه بند Naive Bayes فرض میکند که وجود یک ویژگی خاص در یک کلاس با وجود ویژگی دیگر ارتباطی ندارد. به عنوان مثال، میوه ای اگر قرمز، گرد و حدود 3 اینچ قطر داشته باشد، ممکن است یک سیب در نظر گرفته شود. حتی اگر این ویژگی ها به یکدیگر یا ویژگی های دیگری بستگی داشته باشند، همه این خصوصیات به طور مستقل در احتمال سیب بودن این میوه نقش دارند و به همین دلیل به “بیز ساده” معروف است. ساخت مدل دسته بندی بیز ساده Naive Bayes آسان است و مخصوصاً برای مجموعه داده های بسیار بزرگ مفید است. همراه با سادگی، ثابت شده که این الگوریتم حتی از روشهای طبقهبندی بسیار پیچیده نیز پیشی میگیرد.
ویژگی های naive bayes
ویژگی های naive bayes : الگوریتم دسته بندی بیز ساده Naive Bayes از دو کلمه Naive و Bayes تشکیل شده است که می تواند به صورت زیر توصیف شود: به آن Naive میگویند زیرا فرض میکند که وقوع یک ویژگی خاص مستقل از وقوع سایر ویژگیها باشد. مانند اینکه اگر میوه بر اساس رنگ ، شکل و طعم مشخص شود ، میوه قرمز ، کروی و شیرین به عنوان سیب شناخته می شود. از این رو هر ویژگی به صورت جداگانه کمک میکند تا تشخیص دهد که یک سیب است و بدون اینکه به یکدیگر وابسته باشد. بیز: به آن Bayes گفته میشود زیرا به اصل قضیه بیز بستگی دارد.
به عنوان مثال ، ممکن است سعی کنید عملکرد یک قهرمان المپیک را در طول بازی های المپیک بعدی بر اساس نتایج گذشته پیشبینی کنید. حتی اگر او در مسابقات قبل برنده بوده باشد، به این معنی نیست که این بار برنده خواهند شد. عوامل غیرقابل پیش بینی مانند مشاجره با همسرش امروز صبح یا عدم وقت برای صرف صبحانه ممکن است بر نتایج او تأثیر بگذارد. بنابراین، عدم اطمینان در مدل سازی یادگیری ماشین جدایی ناپذیر است، زیرا زندگی پیچیده است و هیچ چیز کامل نیست. سه منبع اصلی عدم اطمینان در یادگیری ماشین، داده های پر از نویز، داده ناقص مسئله و مدلهای ناقص است.
محاسبه احتمال در یادگیری ماشین، به احتمالات مشروط معروف است. قضیه ی بیز احتمال رخ دادن یک پیشامد را هنگامی که پیشامد دیگر اتفاق افتاده باشد، بدست میآورد. همانطور که در معادله ی زیر مشاهده می کنید، با استفاده از تئوری بیز ،خواهیم توانست احتمال رخ دادن A را هنگامی که B اتفاق افتاده باشد، بدست آوریم. در اینجا ، B شواهد و A فرضیه است. ما به احتمال کلی وقوع چیزی را میتوانیم حدودا حدس بزنیم، اما با توجه به اینکه اتفاق دیگری میافتد احتمال وقوع آن تحت تاثیر دیگر مسائل قرار میگیرد. به عنوان مثال، با استفاده از احتمال مشروط، میتوانیم به این سوال پاسخ دهیم که احتمال برنده شدن یک ورزشکار در مسابقه با توجه به نتایج 10 سال گذشته چیست؟ احتمال شرطی به این ترتیب تعریف می شود: احتمال وقوع A، احتمال مشترک اتفاق افتادن A و B ، تقسیم بر احتمال B.
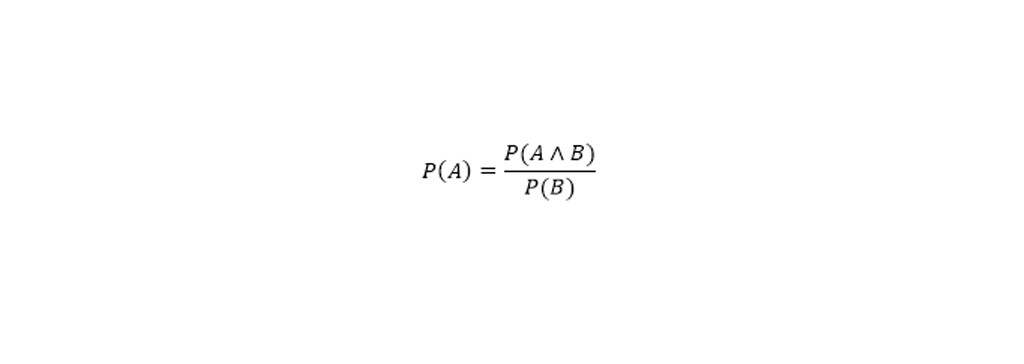
با کمی دستکاری در معادله احتمال شرطی ، می توانید به یک معادله دیگر برسید ، که بیشتر به عنوان قضیه بیز شناخته می شود. بیز ساده را میتوان یک مدل برمبنای احتمال شرطی در نظر گرفت.
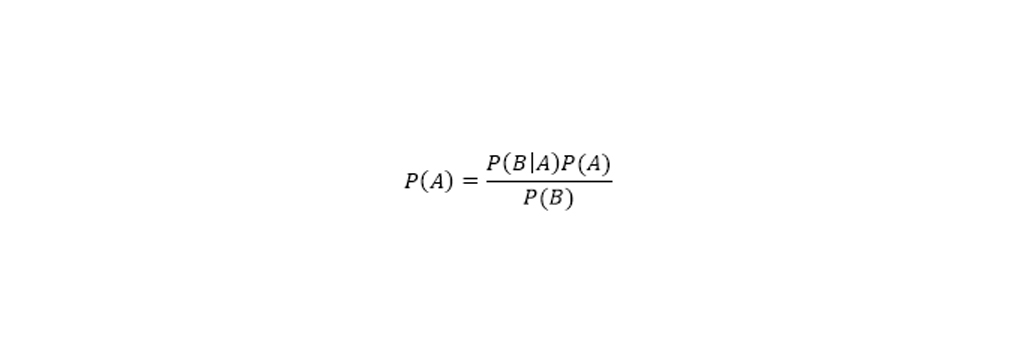
فرض کنید:
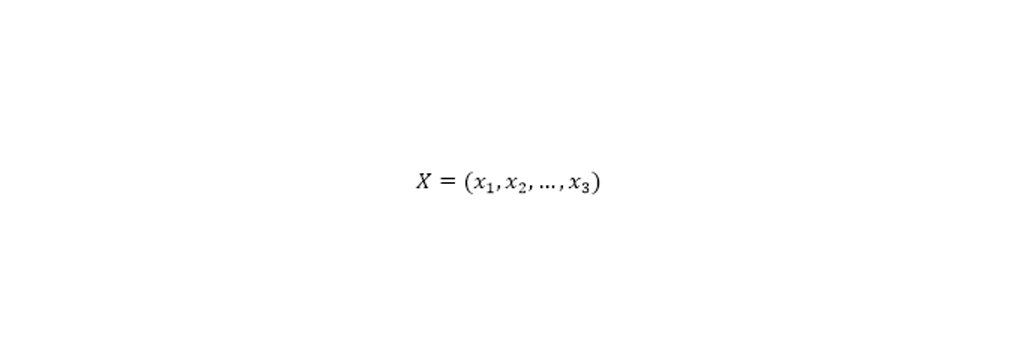
برداری از ویژگی را بیان کند که به صورت متغیرهای مستقل هستند. به این ترتیب میتوان احتمال به صورت زیر در نظر گرفت (احتمال رخداد به ازای های مختلف):
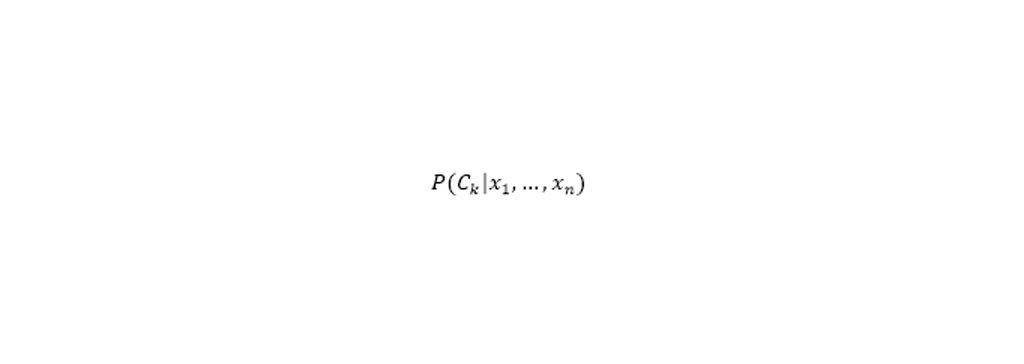
قضیه بیز را براساس احتمالات پیشامدهای «پیشین» (Prior)، «پسین» (Posterior)، «درست نمایی» (Likelihood ) و «شواهد» (Evidence) به صورت زیر میتوان نشان داد:
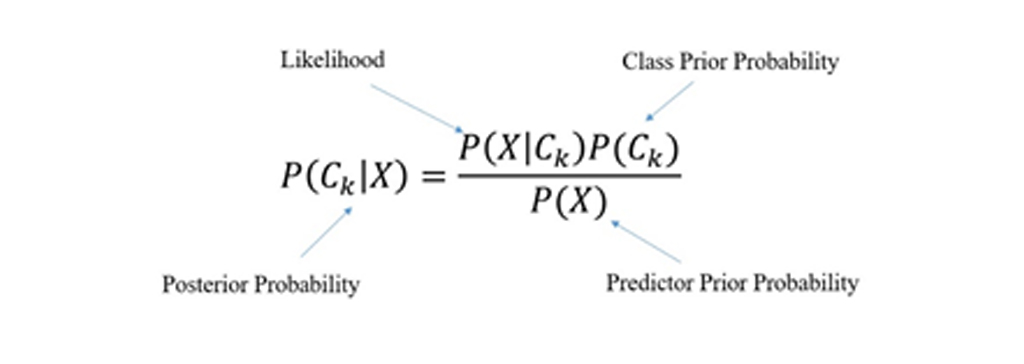
احتمال پیشین A است (احتمال پیشین، یعنی احتمال وقوع یک پیشامد قبل از مشاهده ی شواهد).
شواهد (evidence )، ارزش ویژگی یک نمونه ناشناخته است (در اینجا این رخ داد B است).
احتمال پسین B است که به معنی احتمال وقوع حادثه پس از مشاهده شواهد(evidence) می باشد.
مثال naive bayes
مثال naive bayes : احتمال بیزی به ما امکان محاسبه احتمالات شرطی را میدهد. این بسیار مفید است زیرا ما را قادر میسازد تا از برخی دانش هایی که قبلاً در اختیار داشته ایم برای محاسبه احتمال یک رویداد مرتبط استفاده کنیم. قاعده بیز معمولاً در نظریه احتمالات برای محاسبه احتمال شرطی استفاده میشود. به عنوان مثال، بگذارید برای مشاوره یک ورزشکار در مورد رژیم غذایی قبل از بازی از این الگوریتم استفاده میشود و الگوریتم این داده ها را ارائه میدهد:
در80 درصد از مواقع، اگر برنده مسابقه شود، صبحانه خوبی خورده. P(breakfast|win)
در 60 درصد از اوقات، او یک صبحانه خوب دارد.این حالت.B P(breakfast)
در 20 درصد از اوقات، او در یک مسابقه پیروز میشود. این حالتA . P(win)
با استفاده از قانون Bayes ، میتوانیم:
P (win | breakfast) = 0.8
P(breakfast) = 0.6
P(win) = 0.2

یعنی احتمال برنده شدن وی در مسابقه با صرف صبحانه مفصلی 26٪ است. واضح است که یک بار اضافی از کربوهیدراتها به او تحمل بیشتری در طول مسابقات میدهد. آنچه مهم است این است که ما نه تنها میتوانیم اثبات کنیم که شواهد چگونه احتمال وقوع را تحت تأثیر قرار میدهند، بلکه میزان آن را نیز میدانند.
Naive bayes در یادگیری ماشین
Naive bayes در یادگیری ماشین : الگوریتم دسته بندی بیز ساده Naive Bayes، یک الگوریتم ساده یادگیری ماشین تحت نظارت است که از قضیه بیز با فرضیه استقلال قوی بین ویژگیها برای تهیه نتایج استفاده میکند. این بدان معنی است که الگوریتم فقط فرض میکند که هر متغیر ورودی مستقل است. این مدل حتی با داده های ناکافی یا نامناسب نیز به خوبی کار میکند، بنابراین نیازی نیست که صدها هزار نمونه آن را “تغذیه” کند قبل از اینکه بتوانید چیزی منطقی از آن دریافت کنید.
انواع طبقه بندی الگوریتم دسته بندی بیز ساده Naive Bayes
انواع طبقه بندی الگوریتم دسته بندی بیز ساده Naive Bayes : بسته به نوع داده هر ویژگی، روش متفاوتی مورد نیاز است. به طور خاص، داده ها برای تخمین پارامترها از یکی از سه توزیع احتمال استاندارد استفاده میشوند. در مورد متغیرهای طبقه ای، مانند تعداد یا برچسب ها، میتوان از توزیع چند جمله ای استفاده کرد. اگر متغیرها باینری باشند، مانند بله / خیر یا درست / غلط ، میتوان از توزیع دوجمله ای استفاده کرد. اگر یک متغیر عددی باشد، مانند اندازه گیری، اغلب از توزیع گوسی استفاده میشود.
باینری(Binary): توزیع دوجمله ای(Binomial distribution).
دسته بندی(Categorical): توزیع چند جمله ای(Multinomial distribution).
عددی(Numeric): توزیع گوسی(Gaussian distribution).
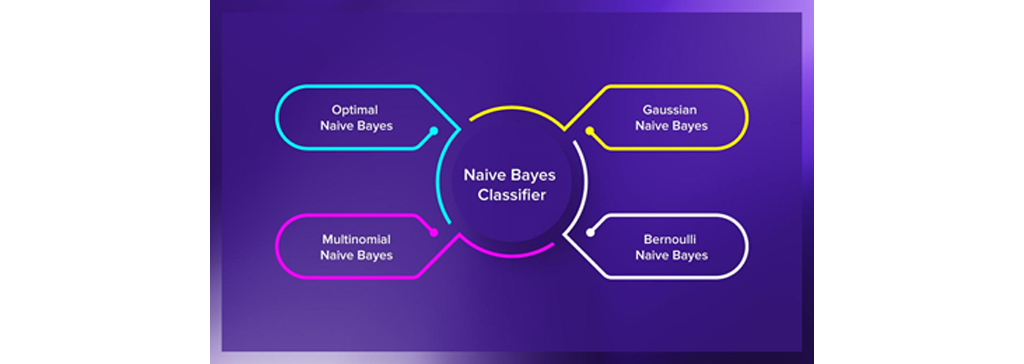
دسته بند بیز ساده گاوسی (Gaussian Naive Bayes):
این ساده ترین طبقه بندی کننده الگوریتم دسته بندی بیز ساده Naive Bayes است با این فرض که برچسب هر داده از یک توزیع ساده گوسی گرفته شده است. این به طور قابل توجهی سرعت جستجو را افزایش می دهد و تحت برخی شرایط غیر سخت، خطا فقط دو برابر بیشتر از Optimal Bayes است.
دسته بند بیز ساده چندجملهای (Multinomial Naive Bayes):
دیگر طبقه بندی کننده مفید الگوریتم دسته بندی بیز ساده Naive Bayes، Naive Bayes چندجمله ای است که در آن فرض میشود ویژگی ها از یک توزیع ساده چندجمله ای گرفته شده اند. چنین Naive Bayes برای ویژگی هایی که ارائه دهنده اعداد گسسته هستند، مناسب تر است. این حالت معمولاً برای مشکلات طبقه بندی اسناد اعمال می شود. تصمیمات خود را بر اساس ویژگیهای گسسته (عدد صحیح)، به عنوان مثال، بر اساس فراوانی کلمات موجود در سند میگیرد.
دسته بند بیز ساده برنولی(Bernoulli Naive Bayes):
مدل مهم دیگر از الگوریتم دسته بندی بیز ساده Naive Bayes ،Naive Bayes برنولی است که در آن فرض میشود ویژگی ها یا پیش بینی کننده ها متغیرهای بولی (صفر و یک) هستند. بنابراین ، پارامترهای مورد استفاده برای پیشبینی متغیر کلاس فقط میتوانند مقادیر بله یا خیر داشته باشند، به عنوان مثال اگر کلمه ای در متن رخ دهد یا نه طبقه بندی متن میتواند یک برنامه کاربردی از Naive Bayes برنولی باشد.
کاربردهای الگوریتم دسته بندی بیز ساده Naive Bayes
از الگوریتم دسته بندی بیز ساده Naive Bayes میتوان استفاده های بی شماری کرد. در اینجا برخی از برنامه های رایج Naive Bayes برای کارهای روزمره وجود دارد:
طبقه بندی اسناد:
این الگوریتم میتواند به شما کمک کند تا تعیین کنید که یک سند مشخص به کدام دسته تعلق دارد. میتواند برای طبقه بندی متون به زبانها، ژانرها یا موضوعات مختلف (از طریق کلمات کلیدی) مورد استفاده قرار گیرد. فیلتر هرزنامه Naive Bayes به راحتی هرزنامه ها را با استفاده از کلمات کلیدی مرتب میکند به همین دلیل از آنها برای حل مسائلی مانند spam-filtering استفاده می شود. الگوریتم باید برای تشخیص چنین احتمالاتی آموزش ببیند و سپس بتواند آنها را به طور موثر دسته بندی کند.
تحلیل احساسات:
بر اساس آنچه احساسات کلمات در متن بیان میشود، Naive Bayes میتواند احتمال مثبت یا منفی بودن آن را محاسبه کند. به عنوان مثال در بررسی مشتری، “خوب” یا “ارزان” معمولاً به معنای رضایت مشتری است. با این حال، Naive Bayes به کنایه و کلماتی که به معنای متفاوتی از خودشان به کار میرود حساس نیست.
طبقه بندی تصویر:
طبقه بندی تصویر برای اهداف شخصی و تحقیقاتی، ساخت طبقه بند Naive Bayesian آسان است، میتوان آن را آموزش داد تا از طریق یادگیری ماشین تحت نظارت، ارقام دست نوشته را تشخیص دهد یا تصاویر را در دسته ها قرار دهد.
پیش بینی در لحظه:
Naive Bayes یک طبقه بندی یادگیری مطمئن و سریع است. بنابراین، میتوان از آن برای پیشبینی در زمان واقعی استفاده کرد.
پیش بینی چند کلاسه:
این الگوریتم به دلیل ویژگی پیشبینی چند کلاس نیز شناخته شده است. در اینجا میتوانیم احتمال چندین کلاس متغیر هدف را پیش بینی کنیم.
سیستم پیشنهادی: الگوریتم naive bayes در داده کاوی
طبقه بندی کننده Naive Bayes و فیلتر کردن مشارکتی با هم یک سیستم پیشنهادی ایجاد میکنند که با استفاده از یادگیری ماشین و تکنیک های داده کاوی اطلاعات نامشهود را فیلتر میکند و پیشبینی میکند آیا کاربر منبع خاصی را می خواهد یا نه. یا اینکه پیشنهاداتی به او ارائه شود که به سلیقه ی او نزدیک باشد. (الگوریتم naive bayes در داده کاوی)
مزایا و معایب تئوری بیز
در ادامه به مزایا و معایب تئوری بیز میپرداریم:
مزایا الگوریتم دسته بندی بیز ساده Naive Bayes
مزایا الگوریتم دسته بندی بیز ساده Naive Bayes : پیشبینی کلاس مجموعه داده های آزمون آسان و سریع است. همچنین با فرض استقلال ویژگی ها در پیشبینی های چند طبقه ای عملکرد خوبی دارد، یک طبقه بندی Naive Bayes در مقایسه با سایر مدلها مانند رگرسیون لجستیک عملکرد بهتری دارد و الگوریتم به داده های آموزشی کمتری نیاز دارد. برای متغیر عددی، توزیع نرمال فرض میشود (منحنی زنگوله، که یک فرض قوی است).
معایب الگوریتم دسته بندی بیز ساده Naive Bayes
معایب الگوریتم دسته بندی بیز ساده Naive Bayes : این الگوریتم در مورد مقادیر طبقه ای بهتر از مقادیر عددی عمل میکند. همچنین، اگر یک متغیر دسته بندی در مجموعه داده های آزمون، دسته ای داشته باشد که در مجموعه داده های آموزش وجود نداشته باشد، مدل به آن احتمال صفر میدهد و قادر به پیشبینی نخواهد بود. به این مسئله مشکل فرکانس صفر گفته میشود. محدودیت دیگر Naive Bayes فرض پیش بینیهای مستقل است. در زندگی واقعی، تقریباً غیرممکن است که مجموعهای از پیشبینی کننده ها را کاملاً مستقل بدست آوریم.
بی اثر کردن الگوریتم دسته بندی بیز ساده Naive Bayes روشی است که توسط اسپمرهای ایمیل استفاده میشود تا سعی در کاهش کارآیی فیلترهای هرزنامه ها داشته باشد که از قانون Bayes استفاده میکنند. این روش با تبدیل کلماتی که قبلاً به کلمات اسپم در یک پایگاه داده بیزی شناخته میشده اند به کلماتی که نشانه ی اسپم بودن را ندارد و یا افزودن کلماتی که احتمالاً در ایمیلهای غیر هرزنامه وجود دارد، این فیلتر را کم اثر کنند. با این حال، آموزش مجدد فیلتر به طور موثری از انواع حملات جلوگیری میکند. به همین دلیل است که از الگوریتم دسته بندی بیز ساده Naive Bayes به همراه اکتشافات خاص مانند لیست سیاه همچنان برای شناسایی هرزنامه استفاده میشود.
جمع بندی الگوریتم دسته بندی بیز ساده Naive Bayes
به طور ساده روش الگوریتم دسته بندی بیز ساده Naive Bayes روشی برای دسته بندی پدیدهها، بر پایه احتمال وقوع یا عدم وقوع یک پدیده است. براساس ویژگیهای ذاتی احتمال (به ویژه اشتراک احتمال) الگوریتم دسته بندی بیز ساده Naive Bayes با دریافت داده های اموزش نتایج خوبی ارائه خواهد کرد. شیوه یادگیری در روش Naive Bayes از نوع یادگیری با ناظر است. برنامههای کاربردی بسیاری هستند که پارامترهای الگوریتم دسته بندی بیز ساده Naive Bayes را تخمین میزنند، بنابر این افراد بدون سروکار داشتن با تئوری بیز میتوانند از این امکان به منظور حل مسائل مورد نظر بهره ببرند. با وجود مسائل طراحی و پیش فرضهایی که در خصوص روش بیز وجود دارد، این روش برای طبقه بندی کردن بیشتر مسایل در جهان واقعی، مناسب است.
نویسنده: تیم پژوهش راهبرد
منابع
towardsdatascience.com


دیدگاه (2)
خیلی ممنون از این بررسی کامل و جامع
سپاسگزاریم.